
はじめに
今回は、RPAツールの中でも、UiPathのある機能についてご紹介していきます。
いろいろな自動化がすでにググればたくさん出てきますが、なかなかググってもすぐに検索できなかったようなものがありましたので、個人的なメモのような形でご紹介していきます。
今回は、動画も用意しましたので、ぜひ最後までご覧ください。
なお、以前にRPAツールの紹介をしましたので、興味がある方は、以下の記事もご参照ください。

- UiPathをすでにインストールされている方
- UiPathでどんなことができるか知りたい方
- WordやPDFを扱う方
- RPAに興味がある方
- はじめに
- 目次
- WordデータをPDFに変換
- PDFのページ数を取得
- おわりに
今回は、PDFデータのページ数を取得するのを目的としておりますが、事前の準備として、PDFがないといけないため、まずはPDFデータを作っていきます。
その前に、PDFは無料で使用できるAdobe Acrobat Readerでは、PDFデータのページ数を増やすことができないので、とりあえず、Wordを10ファイル作って、それを一気にPDFに変換していきたいと思います。
- STEP
Wordデータの作成
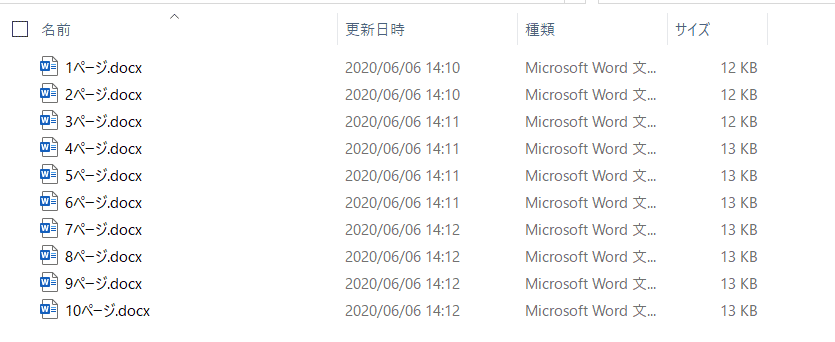
まず、1ページずつページ区切りで10ファイル作りました。もちろんこの作業もUiPathでできますが、こちらは割愛させていただきます。
- STEP
WordをPDFに変換
それでは、WordファイルをPDFに変換していきましょう。
こちらは、一個一個ファイルを開いてPDFにすることもできますが、面倒なので、UiPathでやっていきます。今回は、ページ数取得することがメインなので、こちらについては、またどこかの機会で紹介するとして、動画を用意しましたのでご覧ください。
同じフォルダに入ってしまって分かりづらいかと思いますが、時間の関係で省略させてください。
ファイル名も・・・「.docx」が残ってしまってますね。
今回は、とりあえず、このまま進めます。いずれにしても、準備は終わりましたので、ようやく、PDFのページ数を取得していきたいと思います。

それでは、準備ができたので、続いてPDFのページ数を取得していきたいと思いますが、ページ数をどこかに出力しないと、あまり使い道がないので、今回はExcelに情報を記載していきます。
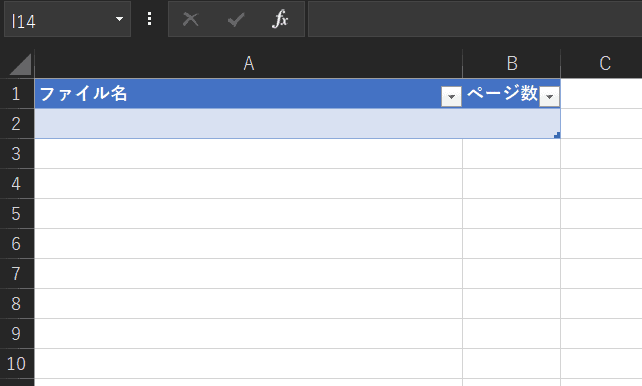
以下のようなタイトルのExcelを用意しておきます。
- STEP
UiPathのフロー
まず、以下のフローをご覧ください。
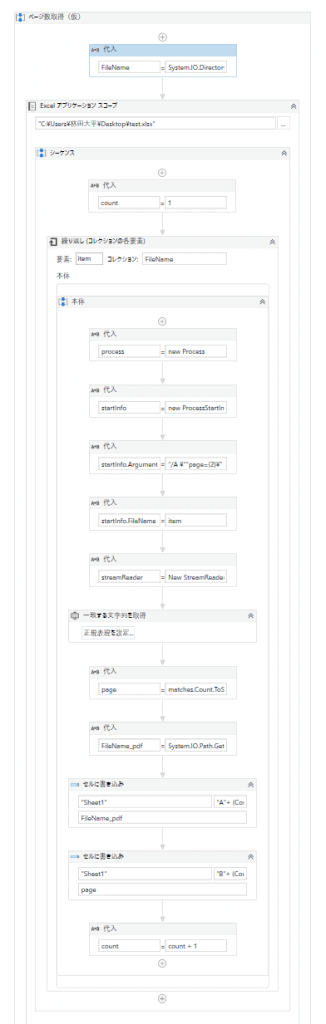
さて、上のフローで、先ほど準備したPDFデータのページ数を取得して、Excelファイルにファイル名とページ数を書き出すことができます。
とてもシンプルで簡単ですね。
・
・
・
・
・
そんなわけないですね。かなり厄介ですよね。
ちょっとずつ分解して解説していきます。
- STEP
ファイル名取得
代入を使って、以下のように入力します。
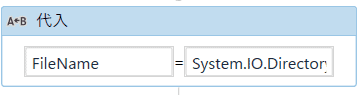
まず、「FileName」という変数を作って、そこに、フォルダ内のファイル名を入れていきます。
以下の式でフォルダ内のファイル名を取得できます。(変数名は適当で大丈夫です。) - STEP
Excelを選択
続いて、Excelを選択します。
以下のようにExcelアプリケーションスコープを使って、残りのタスクはすべてこの中に入れていきます。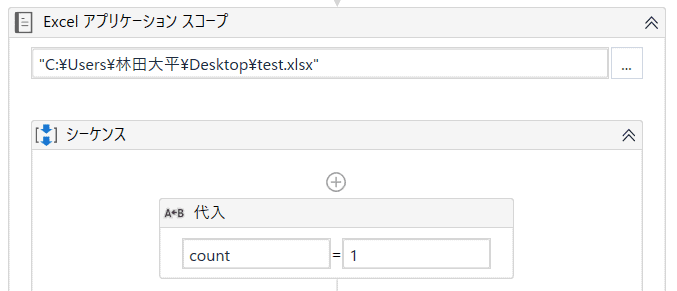
フォルダ先とファイル名を入力(右の…をクリックして選択)して、その中にシーケンスを入れて、繰り返し処理もしたいので、その準備用に代入で「count」という変数を作って、「1」を入れていきます。
- STEP
繰り返し処理
続いて以下のように繰り返し(コレクションの各要素)を追加して、「要素」を「item」(デフォルト値)、コレクションに、STEP2で作成した変数の「FileName」をセットします。
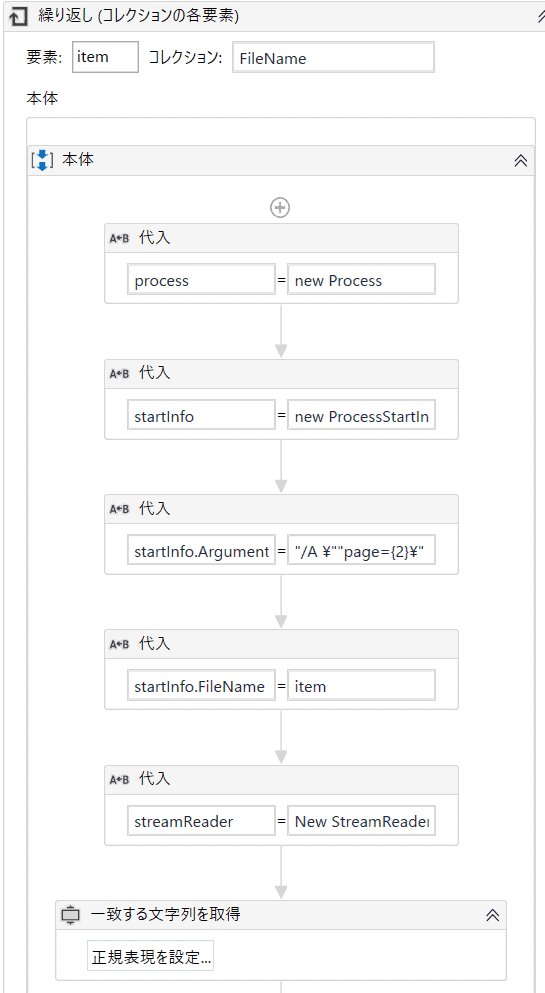
繰り返しの中に、上図のようなおまじないのように、変数を使って、値をセットしていきます。
左側 右側 process new Process startInfo new ProcessStartInfo startInfo.Arguments “/A \””page={2}\” startInfo.FileName item streamReader New StreamReader(File.OpenRead(item)) 代入の後に、一致する文字列を取得を追加して、正規表現の設定をします。
正規表現を設定をクリックすると、以下のようなウィンドウが現れますので完全式というところに以下の式を入れておきます。
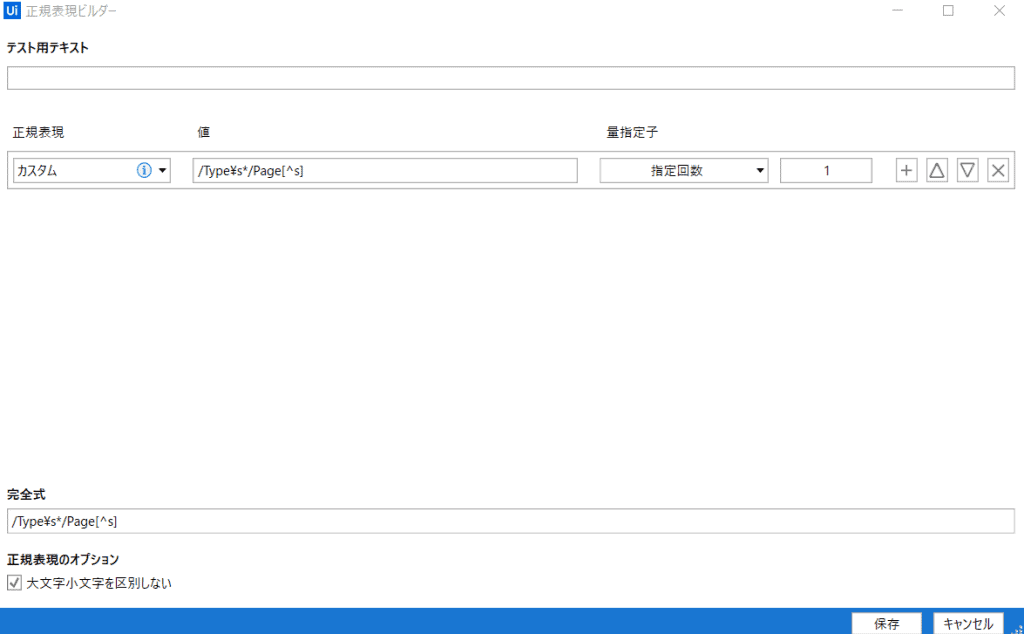
変数 型 process Process startInfo ProcessStartInfo streamReader StreamReader - STEP
Excelに書き込み
さて、ようやく最後のステップで、Excelに書き込むタスクを追加していきます。
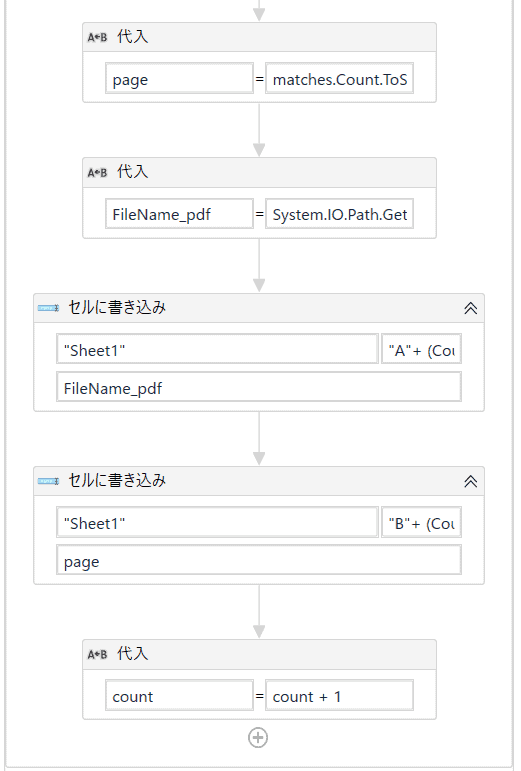
STEP4でいろいろな変数を作りましたが、こちらを使って、取得したページとファイル名を代入で変数を使って書き込む準備をします。
左側 右側 page matches.Count.ToString FileName_pdf System.IO.Path.GetFileName(item) こちらの変数の方は「String」で大丈夫です。
次に、セルに書き込みを追加して、ファイル名を入力させるタスクをいれます。
ファイル名を事前に用意したエクセルのA2から入れたい(A1にタイトルの「ファイル名」があるため)ので、最初のセルの設定を以下のようにします。
続いて、ページ数をB2から入れたいので、こちらは以下のようにします。
最後に、繰り返し処理のために、代入を上図のように入れます。
ようやく、これで完成です。
お疲れさまでした。さて、せっかくなので、こちらを動かした動画を用意しましたので、ご覧ください。

どうやらWordファイルを認識してしまっているようで、若干失敗しましたが、PDFのページ数は取得できました。
フォルダ内にページ数を取得したいものだけ入れておけばうまくいくでしょう。
いかがだったでしょうか。
正直、わたしがまだ全然理解できておりませんのでうまく説明ができず、非常に雑な紹介になってしまった感がありますが、発展途上のためご了承ください。
ただ、わたしはUiPathはまだほとんど使えておりませんが、ちょっと勉強すればこんなこともできてしまいますので、RPAというのは今後の仕事効率化には欠かせないのではないかと思います。
もっといいやり方があるはずではありますが、今回はこのあたりで終わりにします。