
目次
はじめに
今回は、最近、AI等(ディープラーニング)で注目を集めているプログラミング言語である「Python」の面白いライブラリを見つけたので、シェアしたいと思います。
Googleアカウントを持っている方であれば、無料で「Colaboratory」というツールが使用できますので、こちらを使って実装までやってみたいと思います。
ゴール
PDFにある表をExcel、もしくはCSVにして抽出する
準備
早速ですが、PDFファイルに以下の左図のような表があった場合、その表をコピーしてExcelにそのまま貼り付けると、以下の右図のようにおかしなことになった経験はありますか?
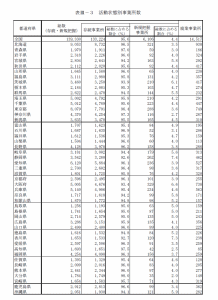
今回は、こちらの表を解消すべく、「Python」の「tabula」というライブラリを使っていきます。
さて、その前に、Pythonを使うために、エディタを用意しなくてはなりませんが、そこで今回はGoogleのColaboratoryというエディタを使っていきます。
こちらは簡単に説明すると、プログラミングを実行するエディタをcloud上で実行できるものとなり、特別ものをインストールしなくても、機械学習をするプログラミング言語がセットされていて、とても便利なエディタとなります。もちろん無料です。
他にも方法がたくさんあって、必要なものをいくつかダウンロードして、PC上にあるコマンドプロンプトから実行することも可能ですが、少々面倒なのと、条件によってはダウンロードがうまくいかない場合もあるので、今回は割愛します。
Colaboratoryの導入まで説明したいところですが、Googleアカウントを持っていれば、「Colaboratory」とググるとわかりやすい情報がたくさんありますので割愛します。

それと、今回、表があるPDFも必要なので、総務省統計局の「令和元年経済センサスー基礎調査」を使いたいと思います。
以下よりダウンロードできます。

実装
さて、Colaboratoryの準備はできましたか?
さっそく始めていきます。
- STEP
tabulaのインストール
- STEP
ライブラリのインポート
次に、以下のコードを打ち、「pandas」「tabula」というライブラリをインポートしていきます。
import pandas as pd import tabula - STEP
「tabula」でPDFを読み込み「pandas」でデータを表示
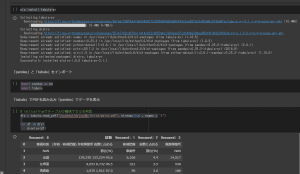
次に、以下のコードを打ち、PDFを読み込んで、Colaboratory上で表の状態を確認していきましょう。
dfs = tabula.read_pdf("/content/drive/My Drive/gaiyo.pdf", stream=True , pages = '8') for df in dfs: display(df)tabula.read_pdfについて、簡単に説明します。
- “/content/drive/My Drive/gaiyo.pdf” Googleドライブ内にあるgaiyo.pdfというファイルを読み込む
- stream=True 表にラインがない場合に使用(格子状になっている場合はlattice=True)
- pages = ‘8’ 表があるページを指定(今回は8ページが対象。全ページの場合は”all”)
さて、ここまで実行すると以下の図のようになるかと思います。
- STEP
Excel/CSVデータへ
さて、最後に以下のコードを打ち、Excel/CSVデータにしていきます。
df.to_csv("/content/drive/My Drive/活動状態別事業所数_pandas.csv", index=None) df.to_excel("/content/drive/My Drive/活動状態別事業所数.xlsx", index=None)上記は、pandasというライブラリ経由でCSV、Excelにしていますが、実は、tabulaで上記ステップ3つを一切気にせず、一気にCSVに変換できます。
tabula.convert_into("/content/drive/My Drive/gaiyo.pdf", "/content/drive/My Drive/活動状態別事業所数_tabula.csv", stream=True , output_format="csv", pages='8')実は、1行だけで、読み込んでCSVに変換することができるんです。
すごくないですか?
これらを実行すると、ほんの数秒で指定のフォルダにExcel/CSVデータができあがります。


おわりに
いかがだったでしょうか?
実は、このファイルを開くと以下のようになります。
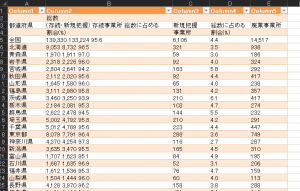
そうです、完璧ではないんですね。
それでも、この後、例えば、B列でスペース区切り等すれば、それなりに使えるデータになるかと思います。
一行のプログラミング言語で上記になるなら、悪くないような気がします。
気になる方は、試してみてください!