
はじめに
前回、Prediction OneというAIの無料ツールについてご紹介しましたが、今回は、「matrixflow」というツールについて、実際に使ってみましたので、ご紹介したいと思います。
- AIに興味がある方
- データ分析を担当される方
- AIについて何かしてみたいがどうすればいいのかわからない方
- はじめに
- 目次
- matrixflowとは
- 実際に操作してみた
- さいごに
今年、2020年2月ころに、株式会社MatrixFlowさんよりリリースされたWEB上で動作するアプリケーションで、機械学習ができるものとなっております。
無料というタイトルではありますが、法人用のベーシックプランと、ある程度の制限がある無料のプランがあって、今回は無料のプランでできるレベルでご紹介します。
詳細は、以下のリンクを参照ください。

- STEP
アカウント登録
まずは、以下のサイトから、「無料ではじめる」をクリックして、必要事項を入力し、WEB上で実際に使えるようにしていきます。
設定自体特にないので、説明は省略します。
- STEP
画面の紹介
まず、「データ管理」という画面になります。
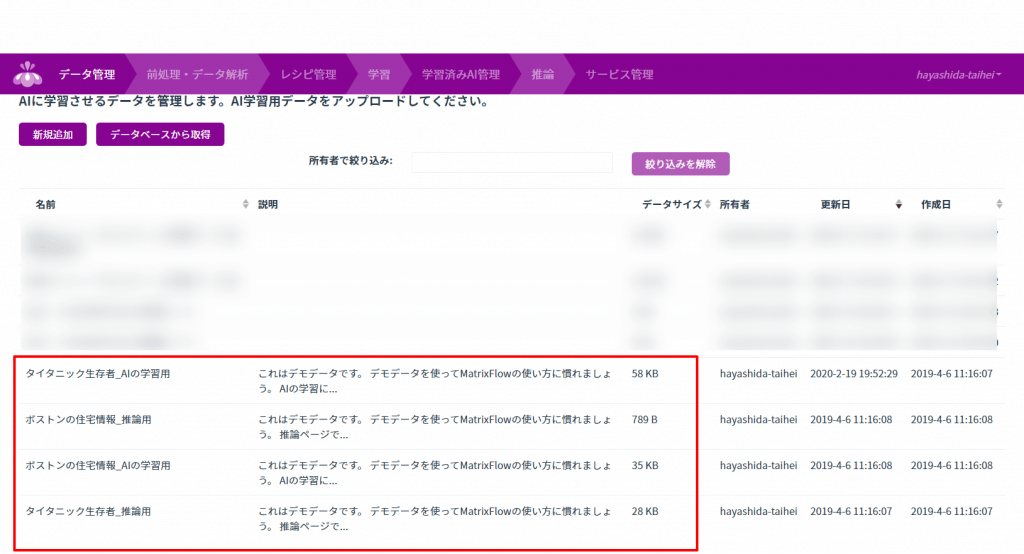
こちらのツールもAIの勉強などで有名なテストデータが用意されておりまして、初期設定でデータセットが上記4つ入っております。
「学習用」と「推論用」と用意されておりまして、通常、機械学習でテストする際は、こちらで用意されているデータのように、学習用のデータでAIのモデルを構築し、その後、推論用のデータで検証して、精度を確認するという手法がとられます。
ただ、前回ご紹介したときもそうですが、このデータをそのまま使っても面白くはないので、今回も、AIでは有名なデータセットでテストしてみたいと思います。
- STEP
データの準備
今回も、「Kaggle」からIrisデータセットという、これも結構有名なのですが、「あやめ」の形とか大きさで、3種類のものに分類するというデータを使っていきたいと思います。

一応、下記サイトからダウンロードできますが、今回も先にダウンロードしたデータをこちらに置いておきますので、ご使用ください。
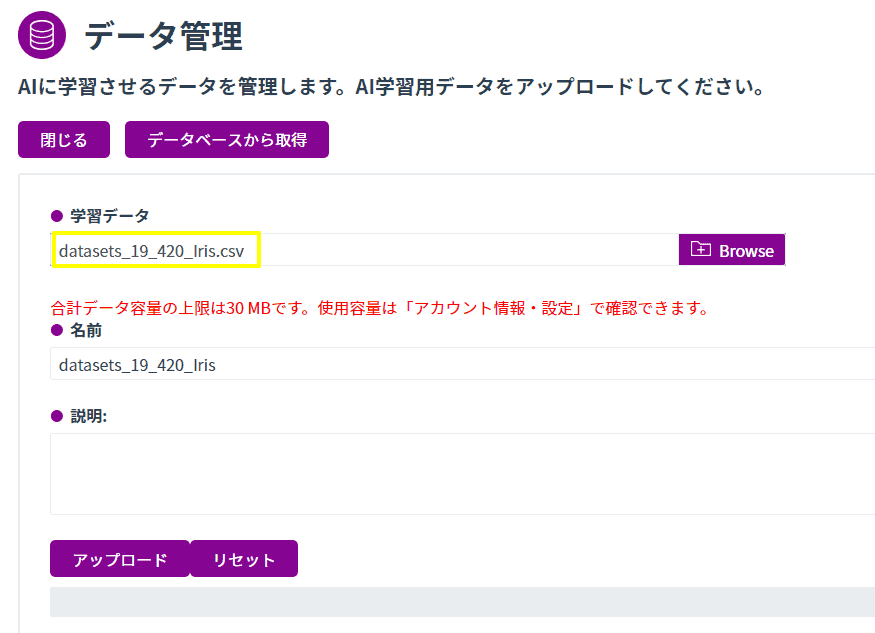
さて、こちらのデータをダウンロードしたら、画面の左上にある「新規追加」でデータを入れていきます。
- STEP
データ整理
次に、データを整理していきます。
一番上のタブの「前処理・データ解析」という項目に移り、先ほど登録したデータを呼び出します。
すると、下図のような統計的なデータと、実際のデータの内容のいくつかが表示されます。
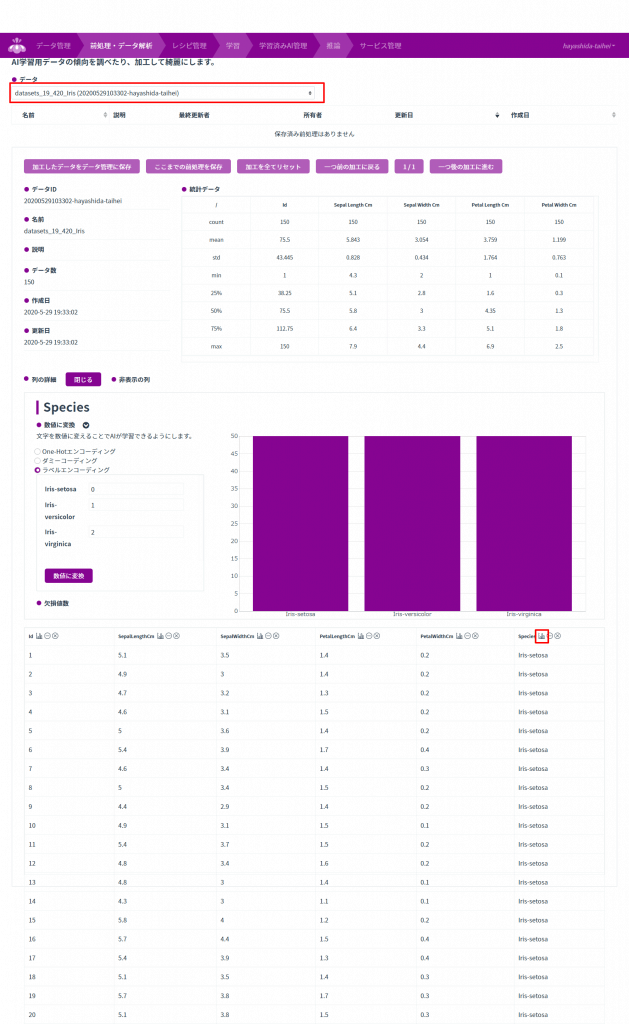
今回のデータは奇跡的に欠損値がなかったですが、分類用の名前は、数値に変換しておかないと、分類できない仕様になっておりますので、こちらを数値に直していきます。
上図の下の表のタイトルで、一番右の「Species」の右にあるグラフのようなボタンをクリックすると、その上にあるようにグラフが表示され、左側に「数値に変換」というのがありますので、そこで、数値に変換していきます。
「数値に変換」をクリックしたら、上にある「加工したデータをデータ管理に保存」をクリックし、加工データを保存します。
データの名前はデフォルトで(前処理済み)となりますので、そのまま保存していきます。
- STEP
レシピ管理
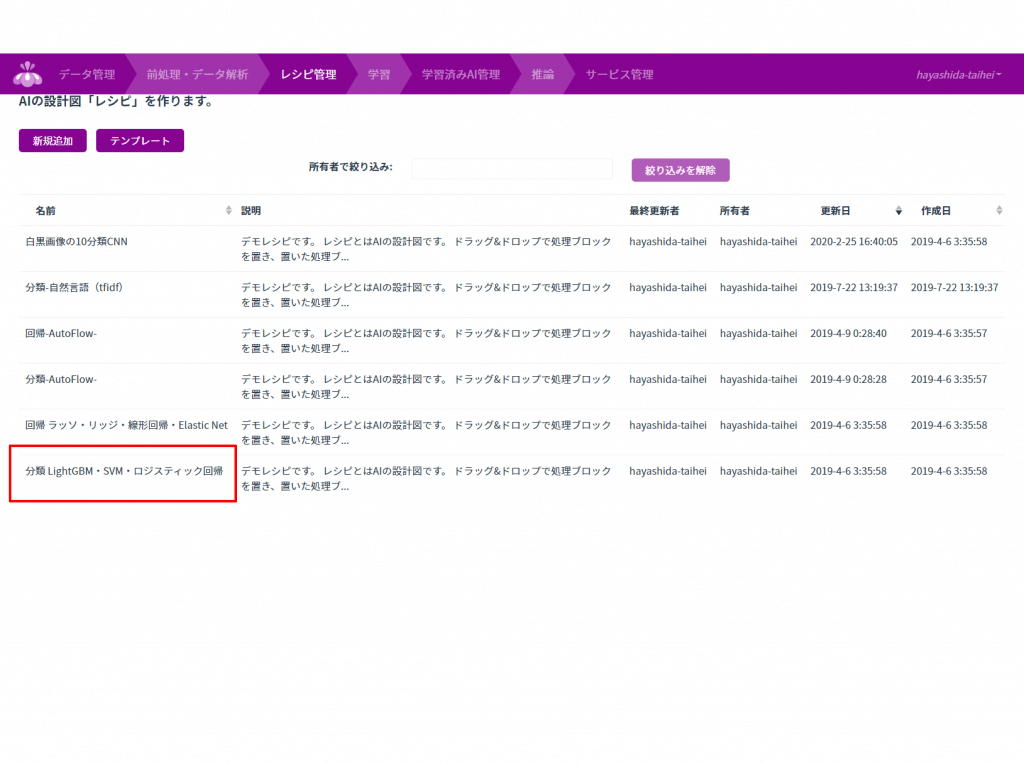
下図の上にある「レシピ管理」に移っていきます。
無料プランですと、こちらのレシピ(アルゴリズム)は追加、編集できませんが、有料プランですと、追加や編集ができるようです。
今回は、無料プランの範疇でやりますので、下図のように「分類LightGBM・SVM・ロジスティック回帰」を使用していきます。
このレシピ選択についてもいろいろと説明できるとは思いますが、今回は、割愛させていただきます。
- STEP
学習
さて、ようやく準備ができましたので、学習に入っていきます。
下図の上側にある、「学習」に移っていきます。
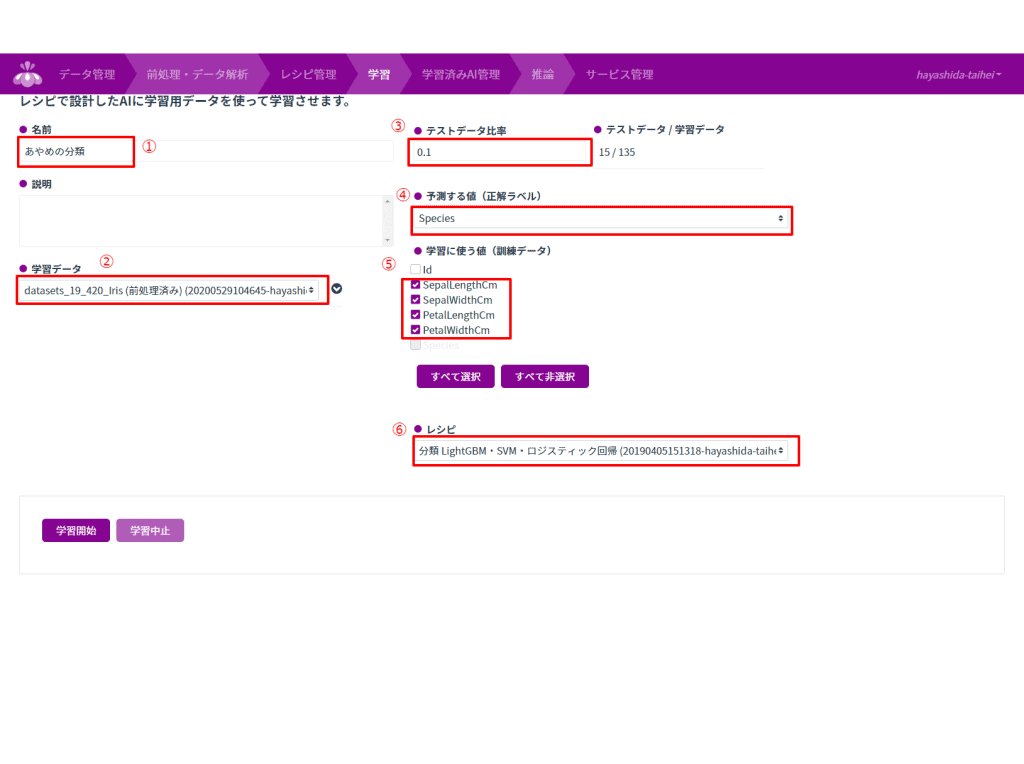
上図のように、6か所設定していきます。
- 学習の名前を入力します。今回は「あやめの分類」としてます。
- 学習データを設定します。「STEP4」で作った前処理済みのデータを選択します。
- テストデータ比率を入力します。今回はデフォルト値の「0.1」とします。
- 予測する値(正解ラベル)を選択します。今回は、あやめの分類を行うので、「Species」を選択します。
- 学習に使う値(制御データ)を選択します。今回は、「id」以外使用していきます。※「id」は分類に関係ないデータなので省きます。
- レシピを選択します。「STEP5」にあるレシピを選択します。今回は、STEP5で説明した通り「分類LightGBM・SVM・ロジスティック回帰」を使用していきます。
設定が終わりましたら、いよいよ「学習開始」をクリックしていきます。
- STEP
結果および評価
学習が終了すると、下図のように結果を示してくれます。

今回の学習時間は「5秒」となりまして、3つのアルゴリズムで評価されてあります。
アルゴリズムやグラフ等に関しての詳細は割愛しますが、かなり高い精度で分類ができていることがわかります。
なお、3種類に分類するのに重要なあやめの要素は、「petal length」すなわち「花びらの長さ」が最も重要であることが分かります。
こちらの要素を計測すれば、どのあやめに属するのかが96%くらいの精度で判別できるということになります。

いかがでしょうか?
実際には、上記のステップで学習モデルを検証し、実際に予測したいデータを用意して、学習で使用したレシピを使用することで、データの予測分析を行うといった形になると思います。
今回のこのような学習モデルでは、ある品種の区別を見極めたいみたいな場合に使えるものとなります。
前回のPrediction Oneと大きく異なる点は、学習のレシピ(モデル)を選択できるところと、データの整理ができることが特徴的だと思います。
今回は欠損値等がないデータでテストしましたが、欠損値がある場合、どのように補うかなどもある程度設定できる仕様となっております。
ぜひ試してみてください。