はじめに
最近、AI技術の進化が目覚ましいですが、実際に仕事で使うというケースまでにはなかなか至っていないという状態ではないかと思います。
その理由の一つとしては、プログラミング知識が必要なのではないかということで、ややハードルが高いし、実際にどうやって始めればいいのかと困ることもあるかと思います。
ただ、ありがたいことに現在は、けっこう簡単に、しかも無料でAIのツールを使える環境にありますので、そのツールをいくつか紹介していきたいと思います。
- AIに興味がある方
- データ分析を担当される方
- AIについて何かしてみたいがどうすればいいのかわからない方
- はじめに
- 目次
- Prediction Oneとは
- 実際に操作してみた
- さいごに
こちらのツールは、昨年の2019年6月ころに、SONYさんからリリースされたデスクトップタイプのアプリケーションで、主に、AIの中でも機械学習のアルゴリズムも用いて、予測分析をするというツールです。
リリース当初、私もAIというキーワードと「無料」というワードだけで飛びついてみました。
ただ、そのころはAIってなにかみたいなところもわからず、手探りで操作してて、「これ何に使えるの?」という感じで、いったんツールから離れました。
しかしながら、最近、AI、特に機械学習やディープラーニングの勉強をしている中で、これって結構すごくない?ということに気づきましたので、今回は実際に実装したことをシェアしてみたいと思います。
Prediction Oneの詳細は、以下のリンクを参照ください。
- STEP
ツールのインストール
まずは、上記のサイトから、「無料で提供中」というところをクリックして、名前や会社名といった必要事項を入力し、ダウンロードしましょう。
そんなに難しいことではないので、インストール方法の詳細は割愛させていただきます。
- STEP
画面の紹介
インストールできたら、次に、セットアップして、ツールを立ち上げてみましょう。
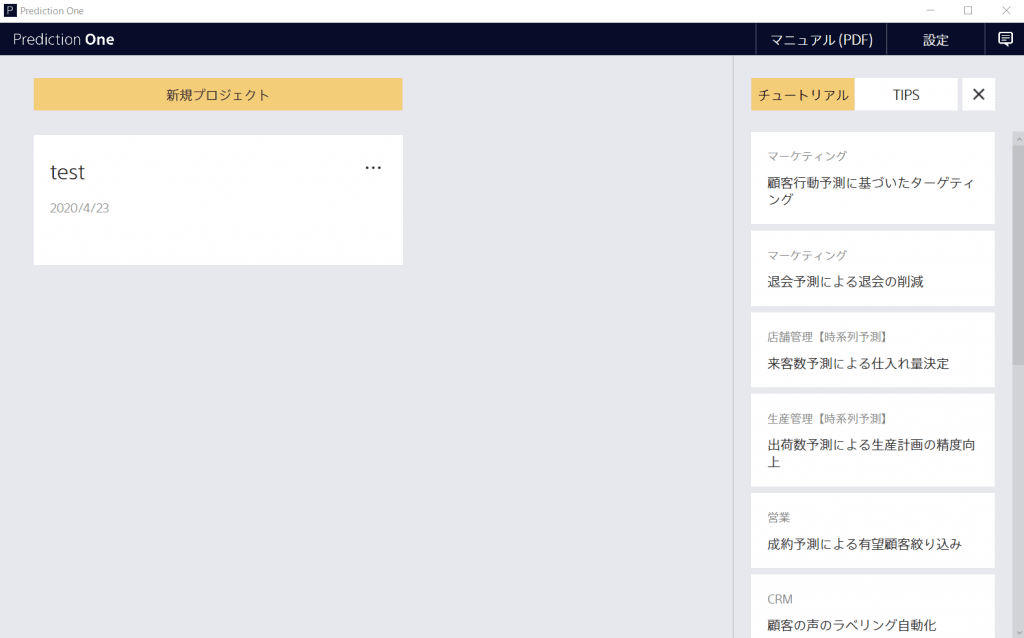
すでに、「test」というプロジェクトを作ってありますが、最初はこちらがない状態だと思います。こちらは非常に親切なマニュアルが右側に用意してありまして、データセットもあって、勉強にもなります。
ただ、今回は、こちらにあるデータを使っても面白くはないので、機械学習でよく使われるデータセットでテストしてみたいと思います。
- STEP
データの準備
まず、AIでは目的が非常に重要になってきます。さらに、その目的のために、必要なデータを準備することが必要になってきます。
データも2,3個あればいいわけではなく、できるだけ多くのデータがある方が、予測精度が上がってきます。
そして、さらに重要なことが、予測する際に、この計算やアルゴリズムも使えば完璧というものはなく、それぞれの目的に合わせた、計算やアルゴリズムを選択する必要があります。
いろいろな課題はありますが、すでに優秀なプログラマーや技術者が精度向上のために研究してくれてますので、とりあえず、あまり深いことは考えずに、よく使われるデータセットを使用します。
「タイタニックで生存者する確率は?」みたいなテーマがあって、そちらのデータが「Kaggle」というAIのコンペティションをやっているコミュニティに公開されておりますので、そちらを使っていきましょう。
上記の参考からダウンロードできますが、やや面倒なので、実際にダウンロードしたデータをダウンロードできるようにこちらに置いておきます。
- STEP
スタート
実際に使っていきましょう。
まず、新規プロジェクトを作成します。
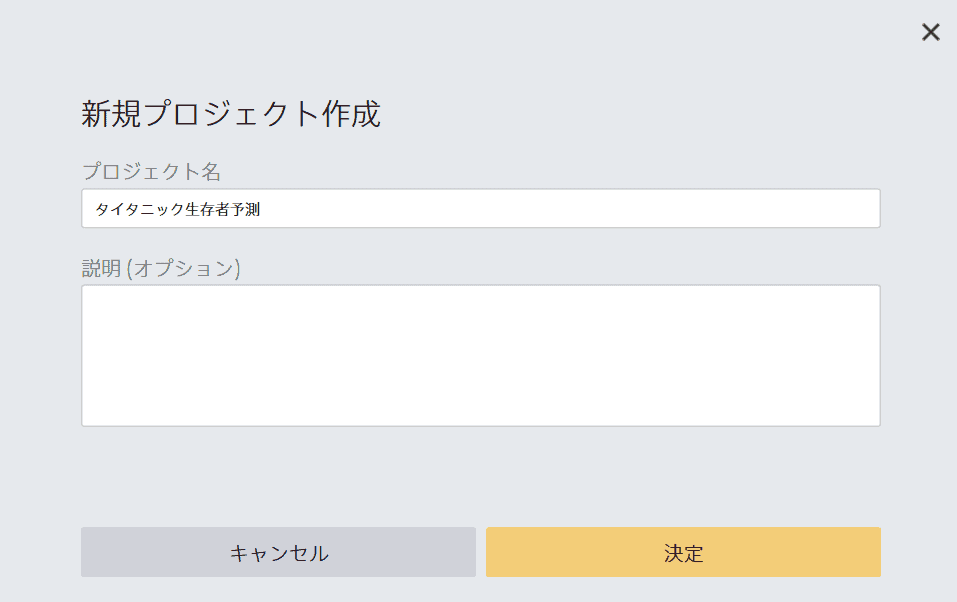
プロジェクト名を入力して、決定をクリックしましょう。今回は、「タイタニック生存者予測」としておりますが、なんでもいいです。
- STEP
新規モデル作成
上記でプロジェクトを作り、次に、データを読み込ませていきます。
「新規モデル作成」をクリックし、STEP3でダウンロードしたデータを読み込ませていきます。
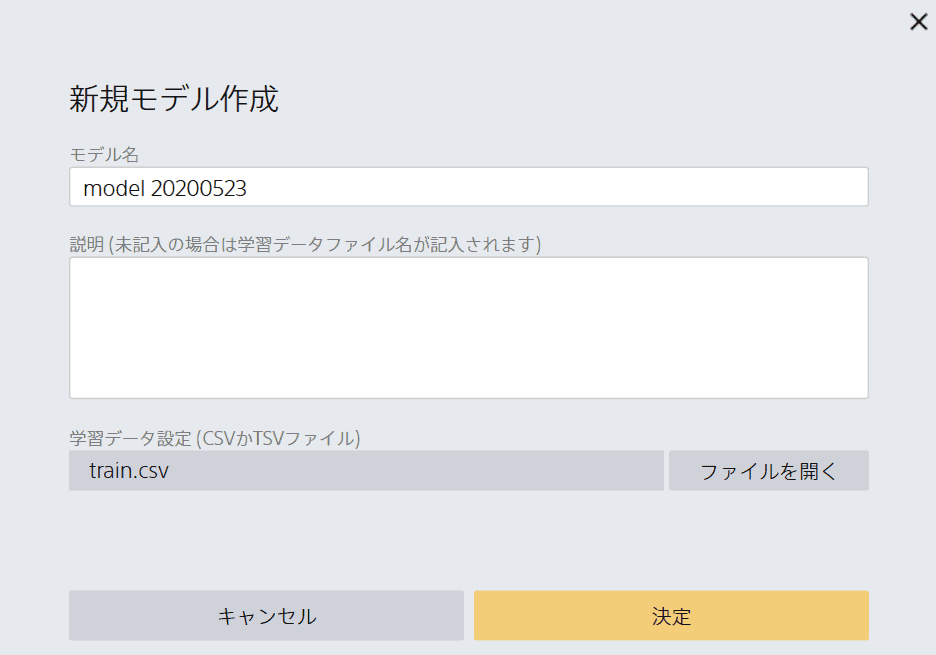
モデル名はなんでもいいですが、デフォルトでは上記のように「model 日付」となっていますので、そのまま進めていきます。
- STEP
データの整理
さて、機械学習をやるなかで、最も難しいのではないかというステップです。
何が難しいかというと、データ自体がまず分析するのに適したものであるケースは非常にまれだということです。
要するに、いろいろとデータを整理してあげる必要があるということになります。
例えば、今回、Nameというタイトルがあり、こちらは乗客の名前なのですが、名前によって、生存するか、しないかみたいなことは相関しない、つまり、関係ないと思われるので、こちらのデータは分析では使わない、とか、Cabinという客室番号?なのかわかりませんが、こちらのデータは約8割欠損しておりますので、削除していくとか、2,3個だけしかデータが欠けていない場合は、なにかの数値で穴埋めする、もしくは、そのレコードだけ削除するとか、まぁいろいろと人手の操作が介入します。
なので、逆に言うと、ここの処理がAI技術者の腕の見せ所なわけです。データから読み取れることやそのデータが今回の目的にどの程度相関しそうかなどを経験や事前の分析などで最適化していくというのが、非常に難しいわけですね。
さて、今回は、そんな難しい部分まで突っ込んでやりませんので、適当にデータを整理していきます。
まず、左上の予測ターゲットを選択します。今回で言いますと、「Survived」つまり、生存したかしないかを予測したいので、これを選択します。
こちらのデータは「0」、「1」で表しているので、「0」が死亡した、「1」が生存したとうことのなります。
続いて、今回使用するデータを選択していきます。
まず、上から順に行きます。
- 「Survived」は予測ターゲットにしましたので、チェックはそのままとします。
- 「Pclass」はよくわかりませんが、パッセンジャーのクラスを表していそうなので、金持ちっぽい人が高いのでしょうか。一応使っていきましょう。
- 「Name」は上記でも書きましたが、使いませんので外していきます。
- 「Sex」は性別なので、一応関係ありそうですので、残しておきます。
- 「Age」は年齢なので、こちらも関係ありそうです、残しておきます。
- 「SibSp」は兄弟姉妹の人数らしいので、こちらは微妙なところです。あまり時間もかけたくないので、今回は外していきます。
- 「Parch」は親または子の数らしいです。これも微妙なところです。「この子のために死ねない」みたいなことがあるかもしれませんが、今回は外していきます。
- 「Ticket」は文字列ですし、面倒なので今回は外していきます。
- 「Fare」は料金です。これはなんか少し関係ありそうなので残しておきます。
- 「Cabin」は上記でも書きましたが、外していきます。
- 「Embarked」はよくわかりませんので、外していきます。
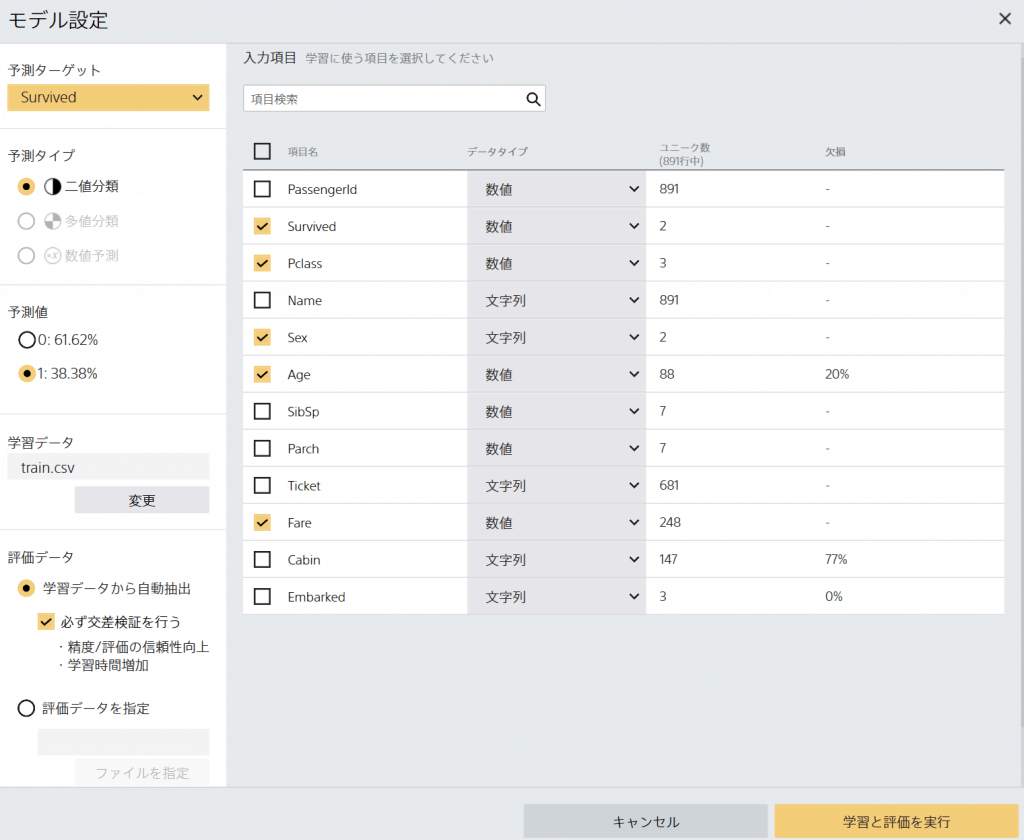
さて、上図のようになりましたでしょうか。評価データの部分は「必ず交差検証を行う」にチェックを入れておきます。これも説明すると長くなりますので、割愛します。
簡単に言えば精度が上がります。が時間がかかります。
「評価データを指定」これも今回は割愛します。
- STEP
学習
データの整理ができたら、「学習と評価を実行」をクリックしましょう。
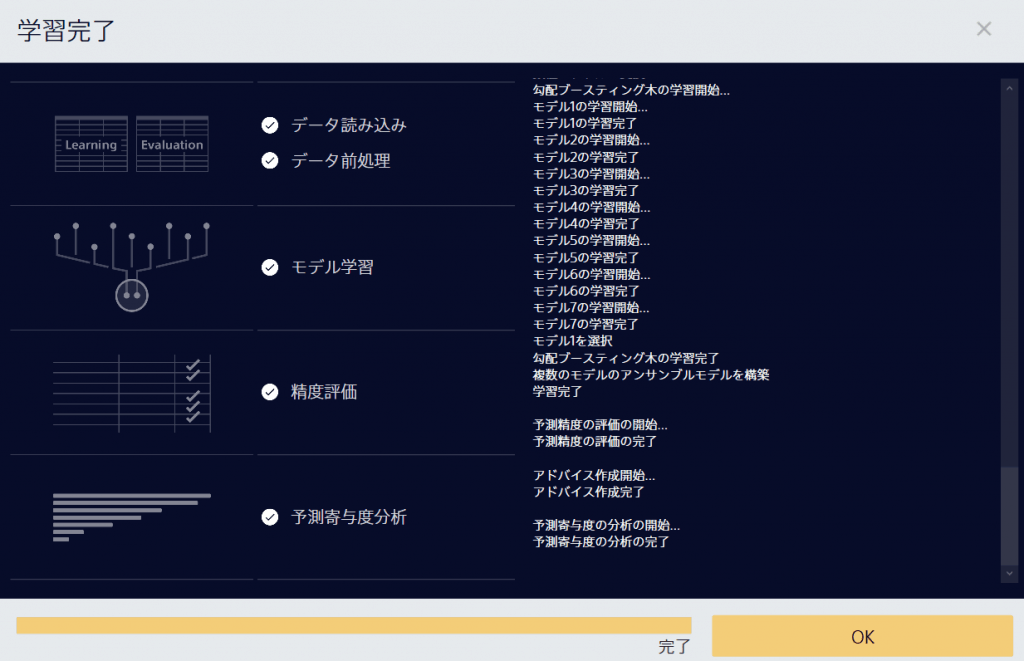
上図のように、学習過程も示してくれます。
アンサンブル学習も行ってくれております。
- STEP
結果および評価
学習が終了して、「OK」をクリックすると結果を示してくれます。
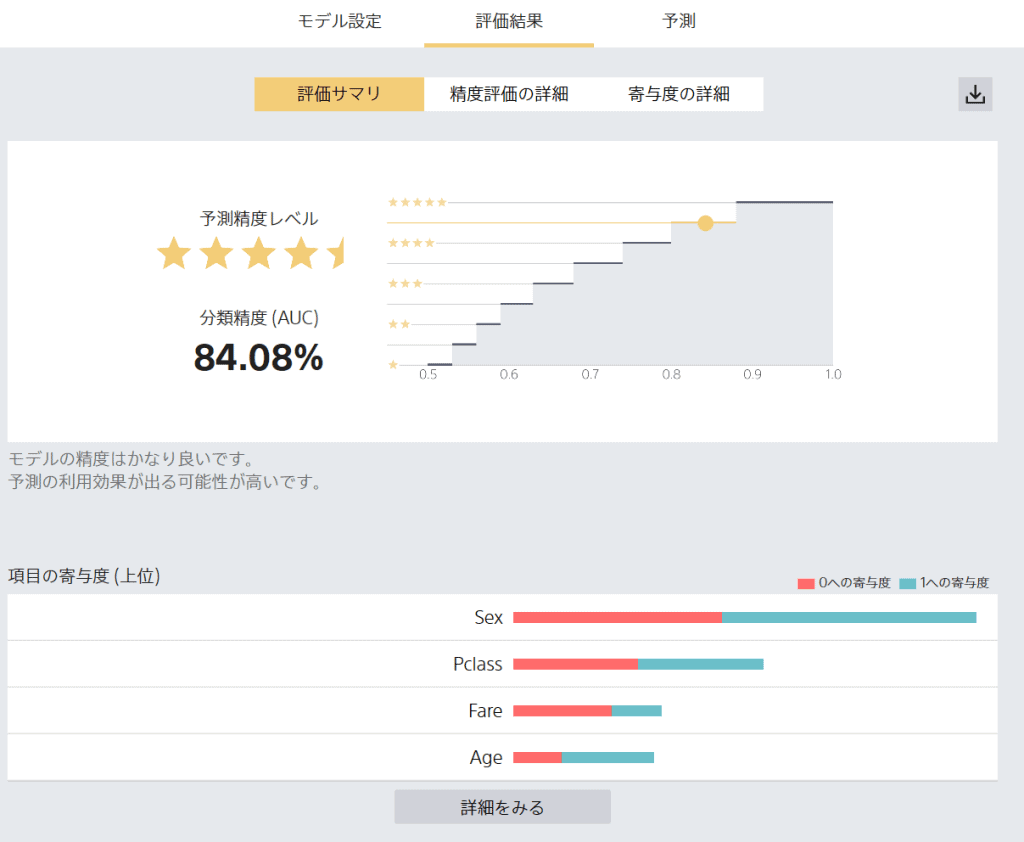
上図のように、約84%の精度で学習できています。
こちらの学習結果からすると、性別が生存するのにかなり影響がありそうだという結果となっております。男性より女性の方が生存しやすいようですね。
「詳細を見る」でいろいろと分析データが紹介されます。
それぞれの説明は、結局のところ、データをどのように評価するかは個人の価値観の違いもありますので、今回は割愛します。
いかがだったでしょうか?実際に操作してみたら意外と簡単だったと思います。
ですが、大事なことは、目的をどう設定するか、データをどのように集めるか、最終的に出てきたデータをどのように評価するか、これらのことは、ロボットが勝手にやってくれることではありません。
正しい知識を身につけて、うまく活用していければいいと思います。
最後までご覧になっていただきありがとうございました。