
目次
はじめに
さて、前回に引き続きMicrosoft Azureの機械学習で遊んでみましたので、そちらのシェアをしたいと思います。
ちょっとタイトルが大げさに思えるかもしれませんが、正直、あと数年したら、高校生がこのくらいの知識があるレベルを想定した場合、経営者がこのくらいの知らないとマズいなと思いましたので、今回はこのようなタイトルにさせてもらいました。
前回、自動でアルゴリズム等を設定するやり方でテストしましたが、今回は、自らモデルを構築するというかなり面白い設定に関して紹介したいと思います。
今回のテーマとしては、自動車の価格を予測するという回帰問題について取り上げていきます。
前提条件
前提条件としては、基本的に前回の記事(上記)と同様になっておりますので、できれば上記記事をご覧の上でこちらの記事をご覧いただければと思います。
実装動画
細かい設定についてはこちらの記事で記載しきれない部分がありますので、ぜひ、動画をご覧いただき、どのように使っていくのかを確認いただければと思います。
説明
前回同様にMicrosoft AzureのMLについての学習を見ながら動画を撮影しておりますので、そのラーニングシステムを見ていただいたらいいかとは思いますが、流れや、重要そうなポイントだけちょっとだけ解説したいと思います。

- STEP
データセットの設定
今回は、Microsoft側ですでに用意してくれているデータセットを使っていきます。
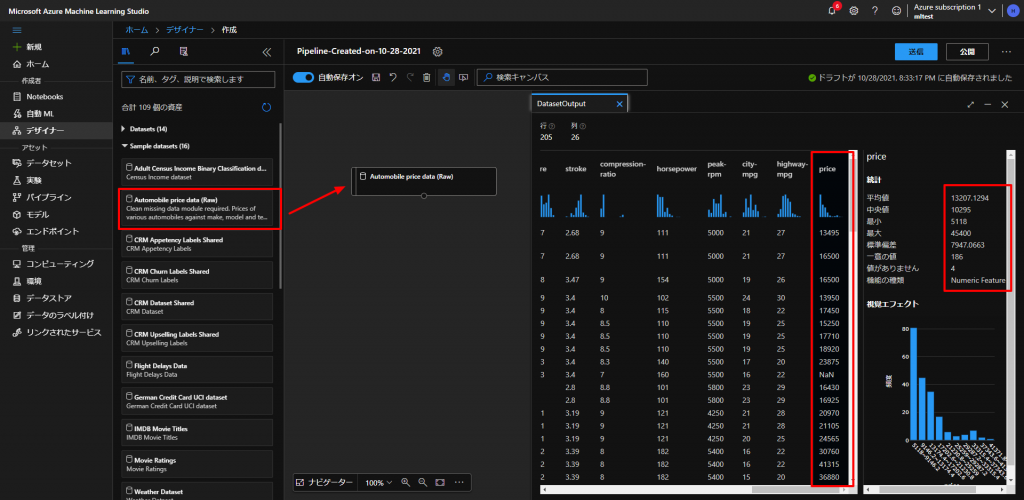
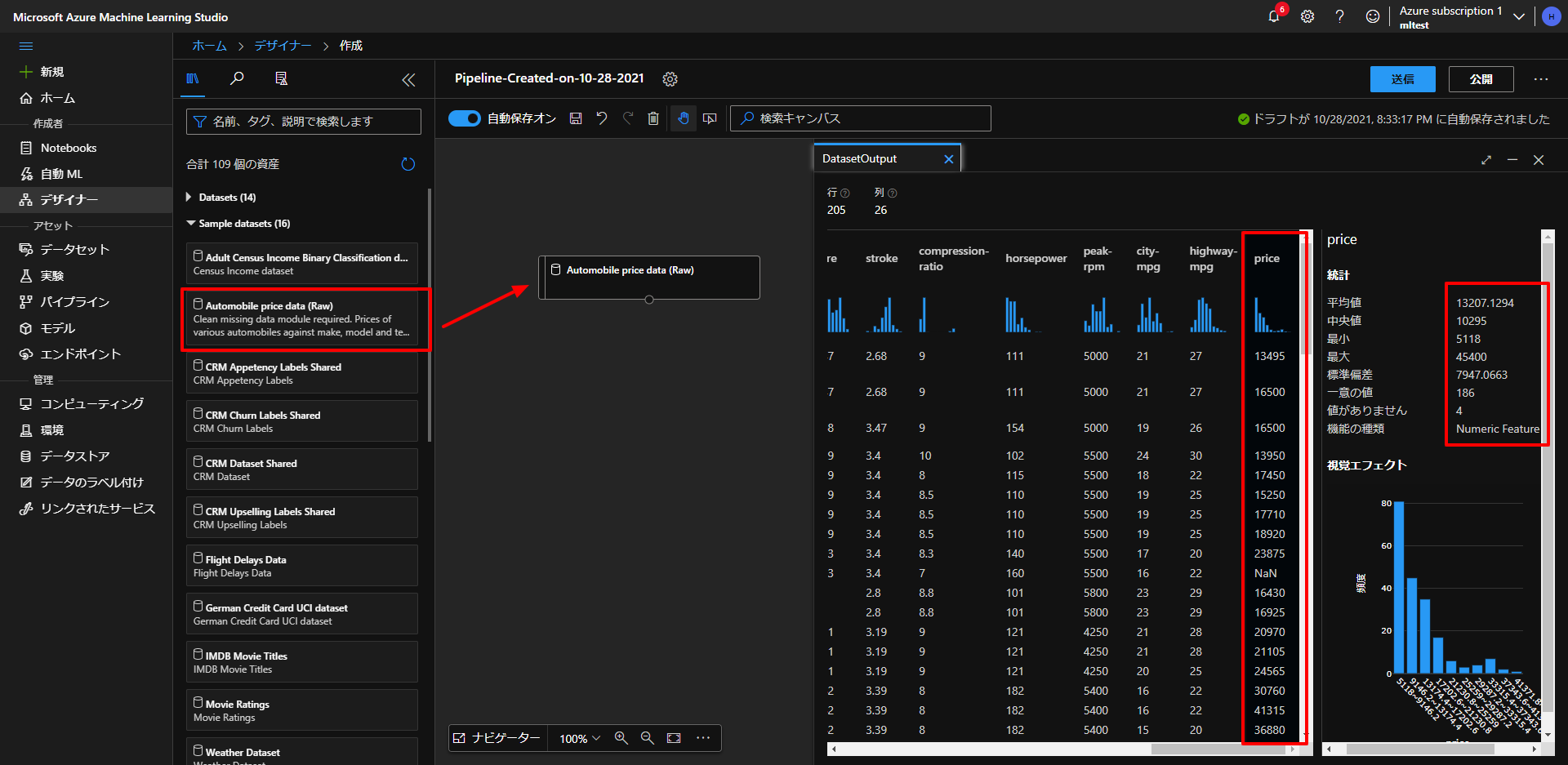
上図のように、一番左のデザイナーという項目から、新規作成して、Sample datasetという中からAutomobile price data (row)というものを真ん中の何もないところにドラッグアンドドロップしていきます。
すると、画面の右側にデータセットのウィンドウが立ち上がり、そのウィンドウの出力タブのDataset outputの棒グラフのようなアイコンをクリックすると、上図右の画面のようにデータの詳細が確認できます。
今回は、このデータの中で、一番右にあるPrice(価格)を予測していきます。
上図のようにデータの列をクリックすると、その詳細がさらに右側に表示されて統計データが確認できます。
- STEP
データの選択
続いて、機械学習で使用したいデータを選択します。
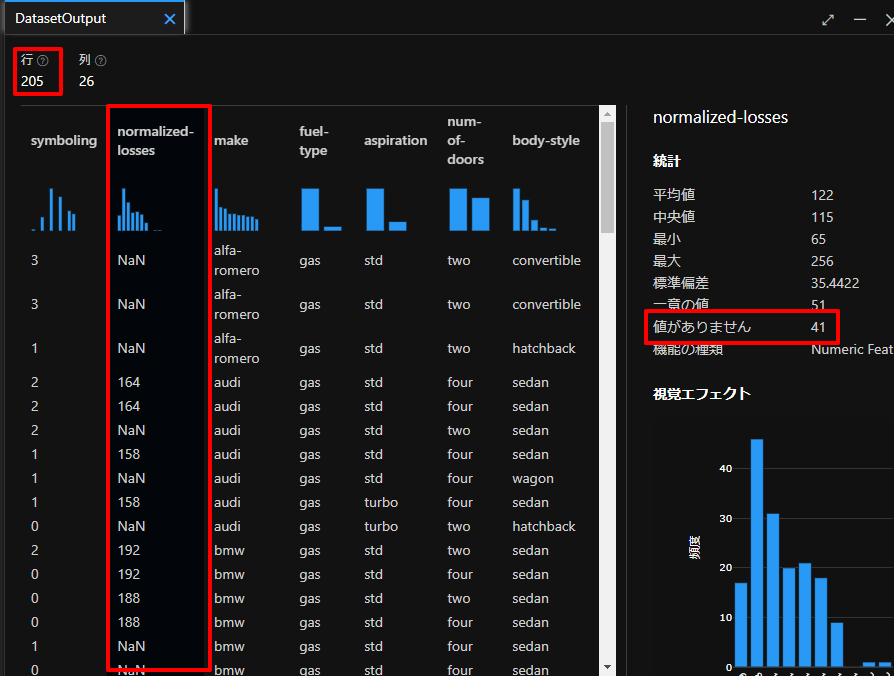
上記のデータセットを眺めてみると、normalized-lossesというデータが205個のデータ中で41個も欠損しており、全体の20%も欠損しているため、今回はこちらのデータは使わないで、その他のデータを使っていきます。
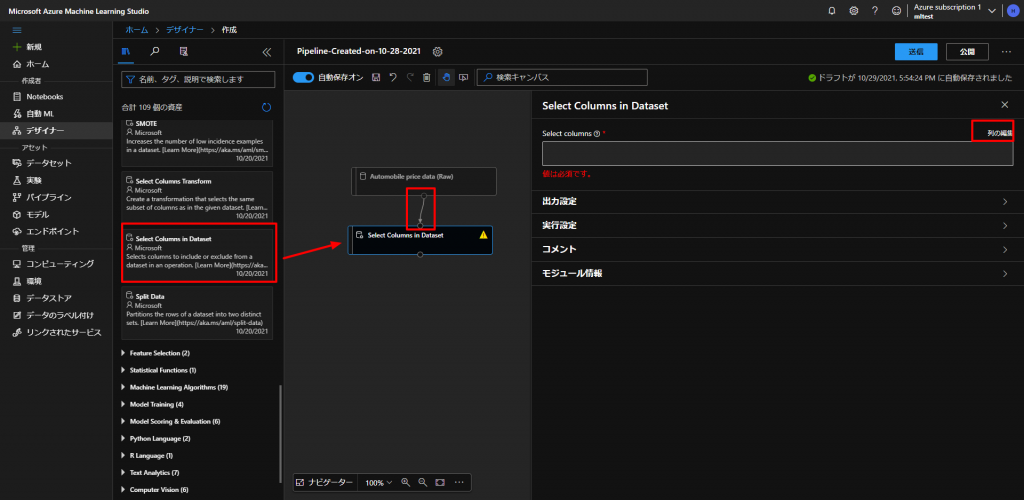
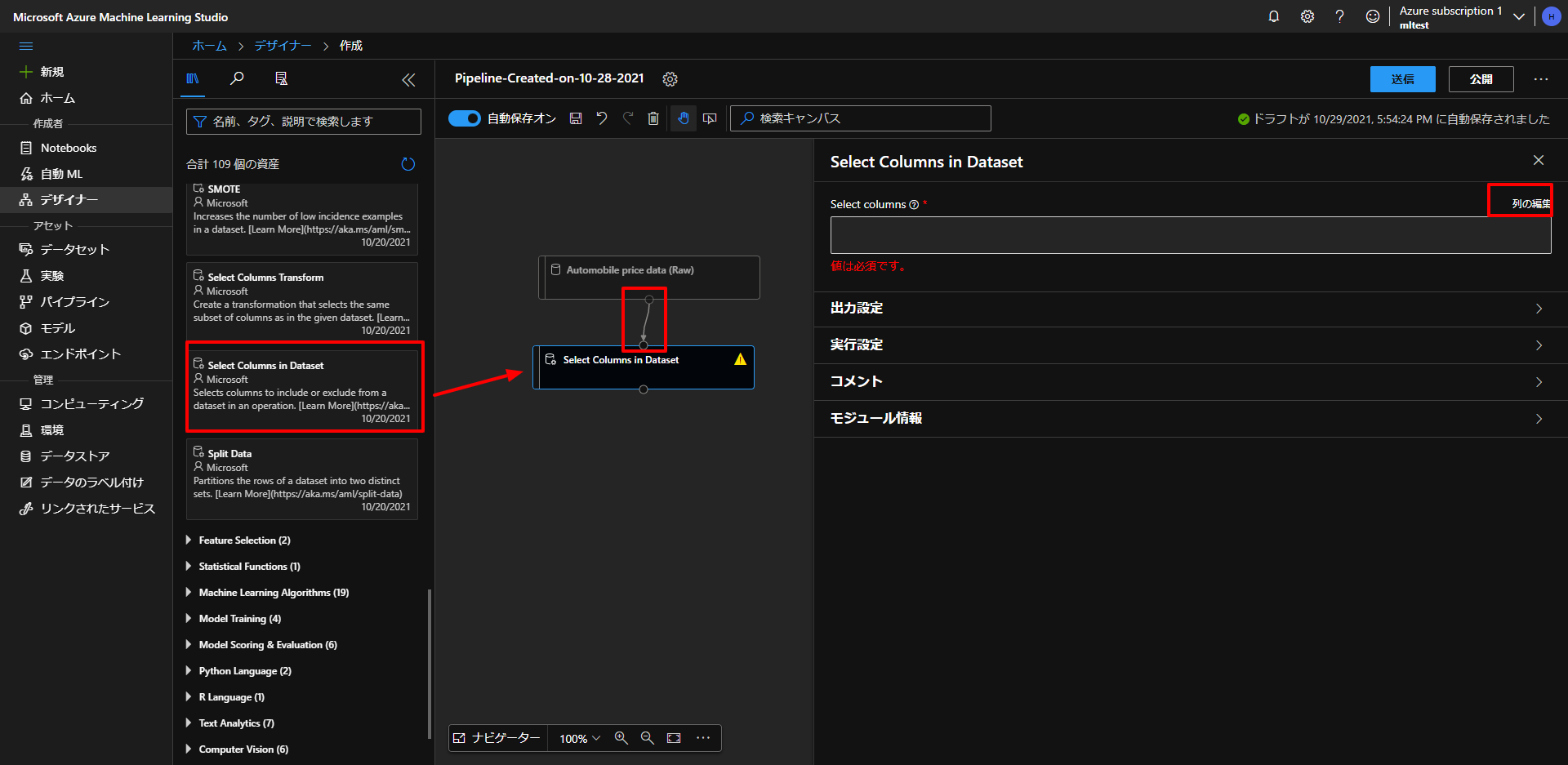
上図のように、Data TransfomationからSelect Columns in Datasetをドラッグアンドドロップして、 Automobile price data (row) とつなぎます。
今回は、 normalized-losses のデータ以外のデータで、機械学習をしていきますので、それ以外のデータを選択していきます。
上図の、Select Columnsの列の編集で下図のように、すべて追加をクリックした後で、 normalized-losses を右の選択した列からマイナスボタンを押して、削除します。
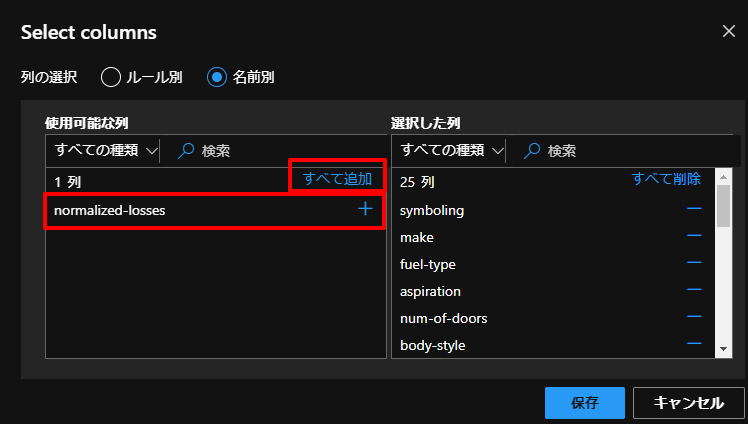
- STEP
欠損値の処理
続いて、いくつかのパラメータで欠損値がありましたので、こちらのデータを加工していきます。
欠損値をどうするのかについては、これもやはりデータを扱う人のスキルによるところになりますが、今回は、欠損値のレコード(行)を削除していくことにします。
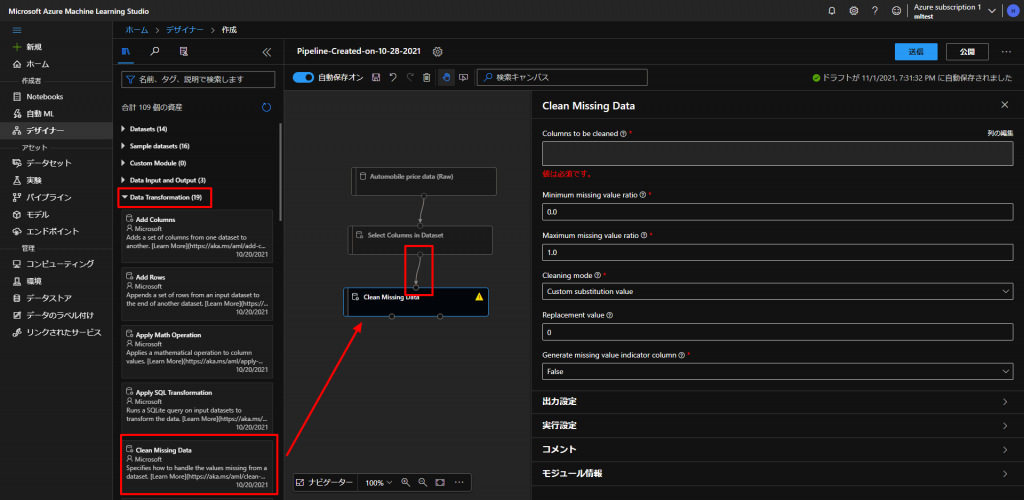
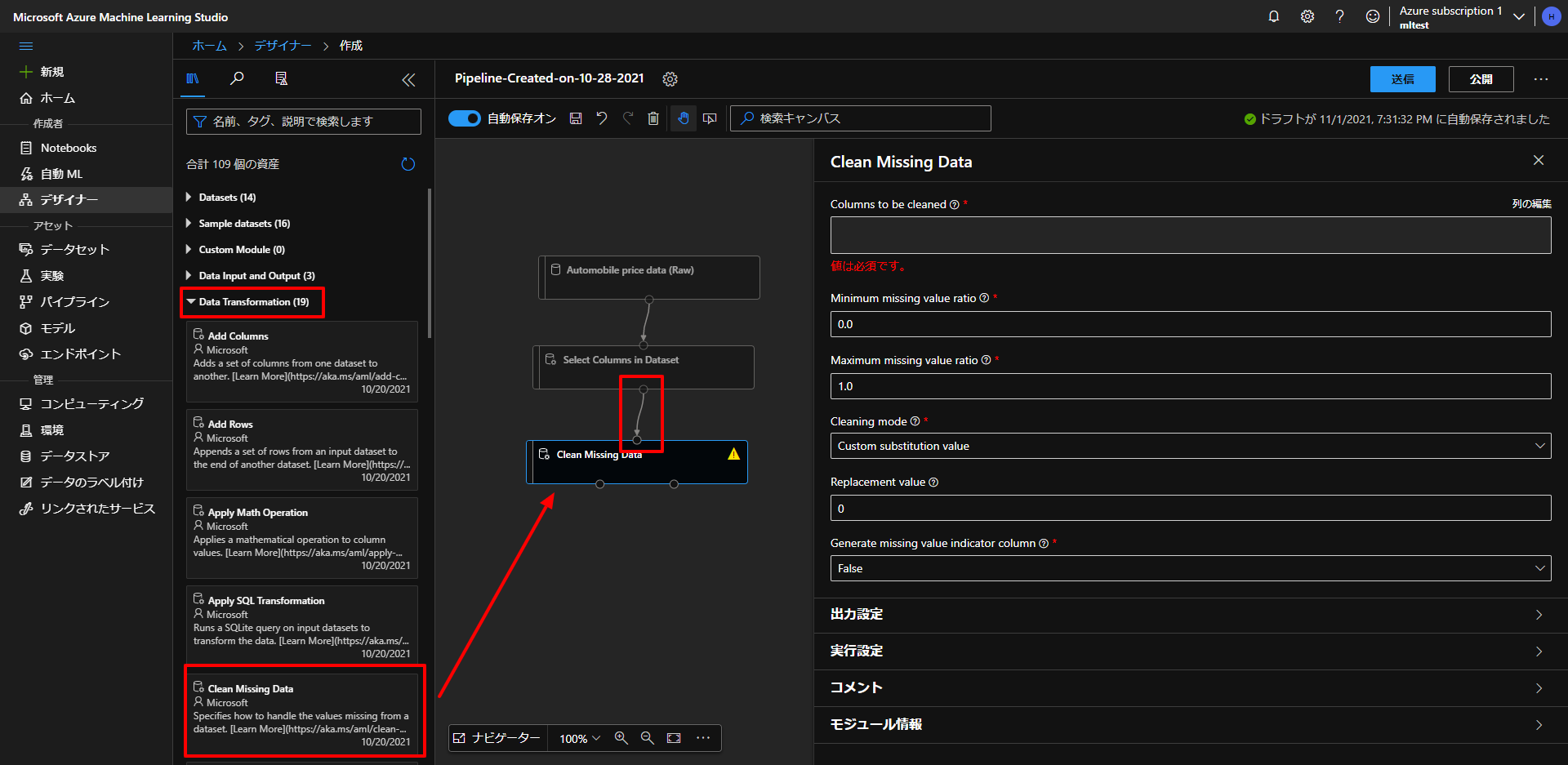
上図のように、Data TransfomationからClean Missing Dataというものをドラッグアンドドロップして、上とつなぎます。
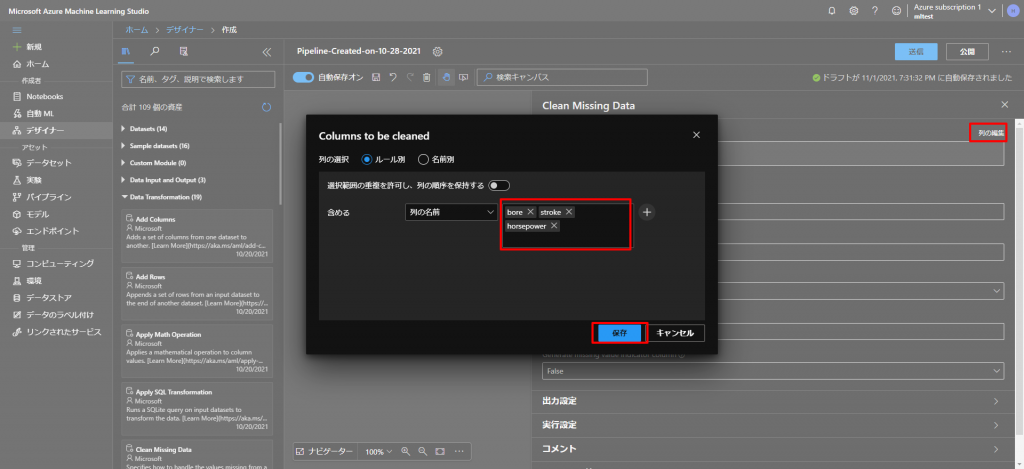
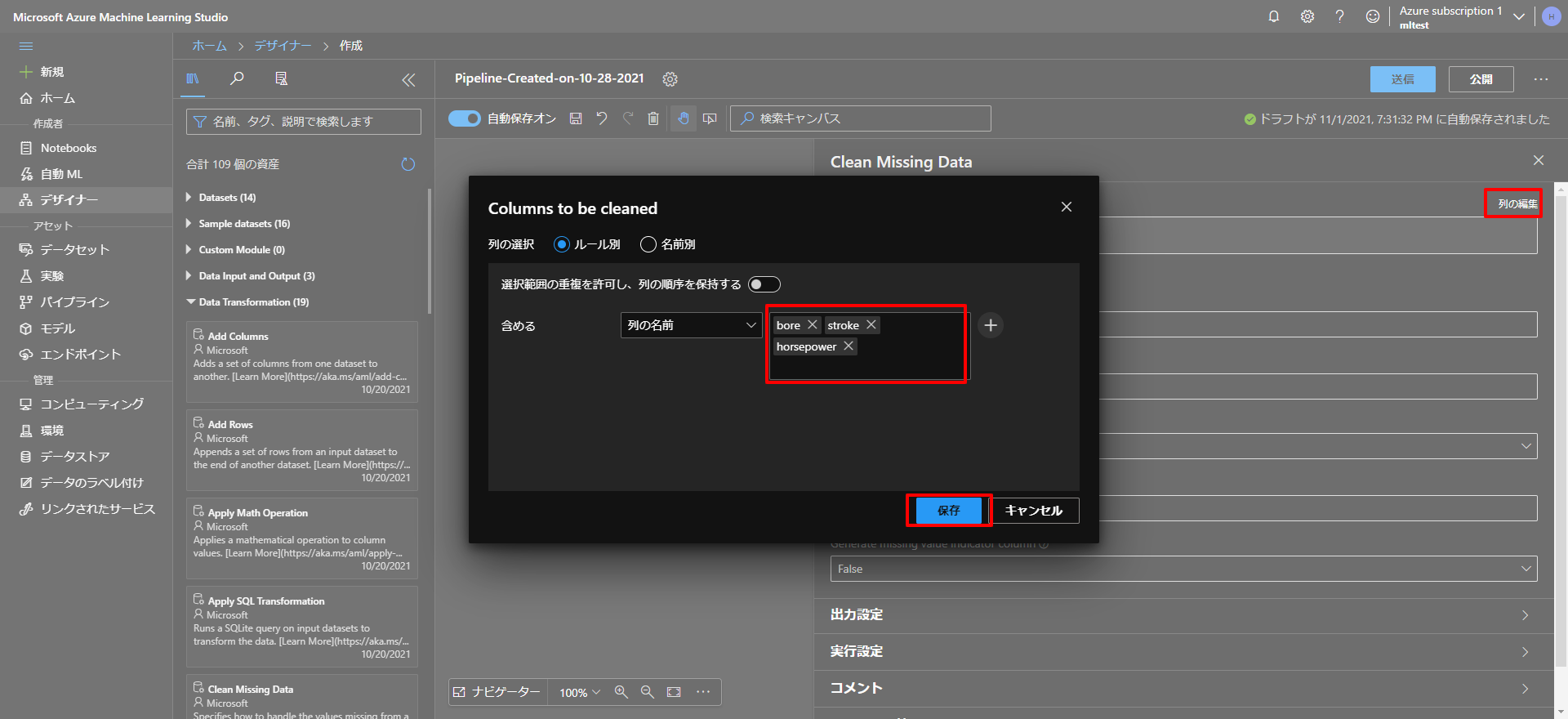
続いて、上図のように、列の編集をクリックして、今回は、欠損値を含んでいる列のbore、stroke、horsepowerを選択して保存します。
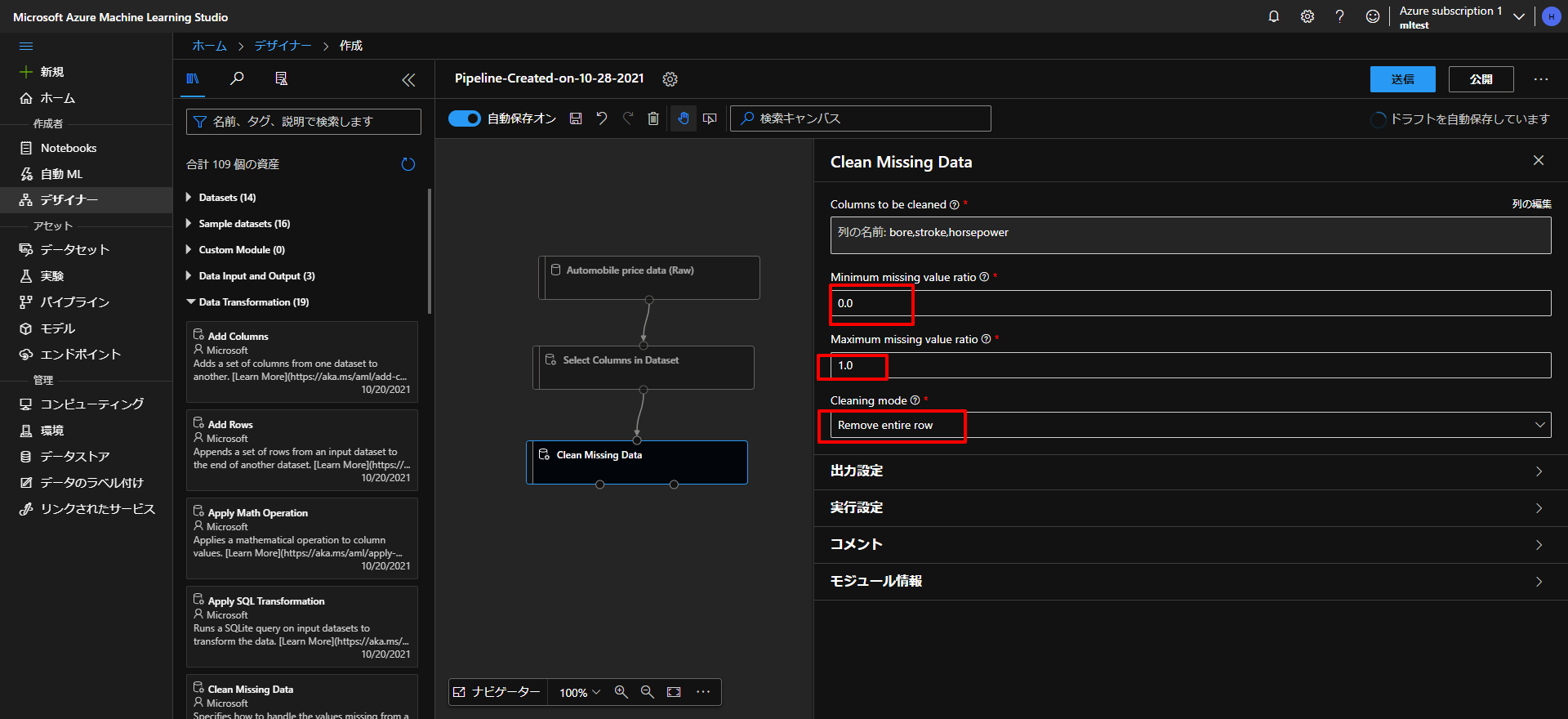
続いて、下図の通り、Minimum missing value ratioを0.0、Maximum missing value ratioを1.0、Cleaning modeをRemove entire rowに設定します。
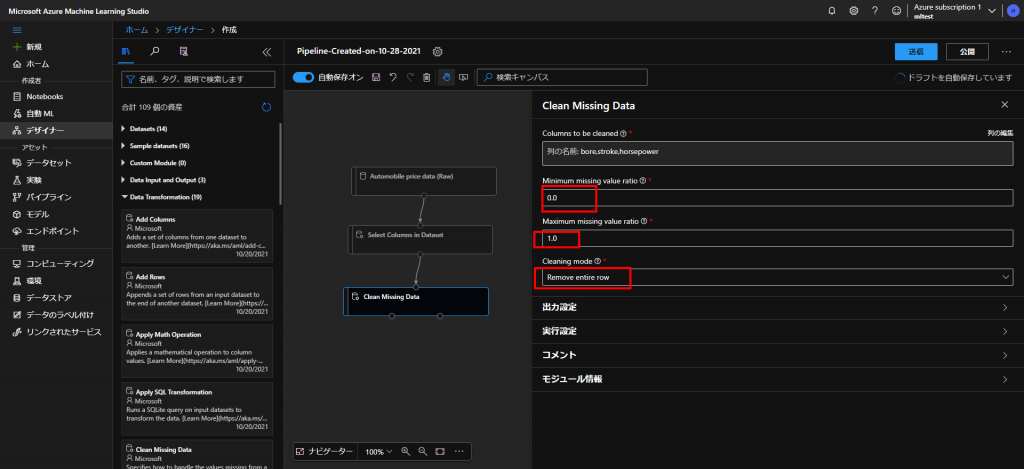
- STEP
データの正規化
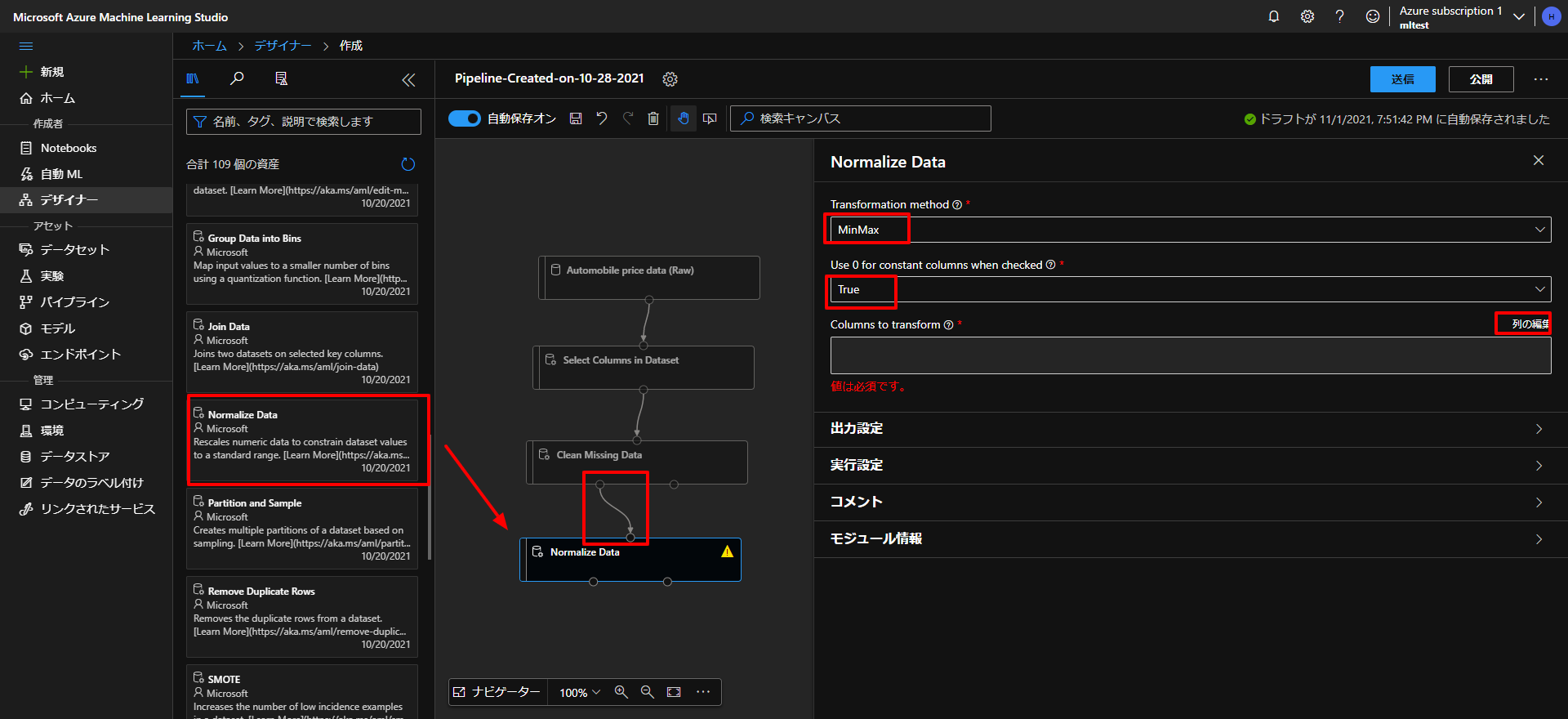
これは、前回同様に、正規化という作業が必要になりますので、下図のように、 Data Transfomation からNormalized Dataをドラッグアンドドロップして、上とつなぎます。
また、前回同様にTransformation methodはMinMax、Use 0 for constant columns when checkedはTrueにして、Columns to transformの列の編集をクリックします。
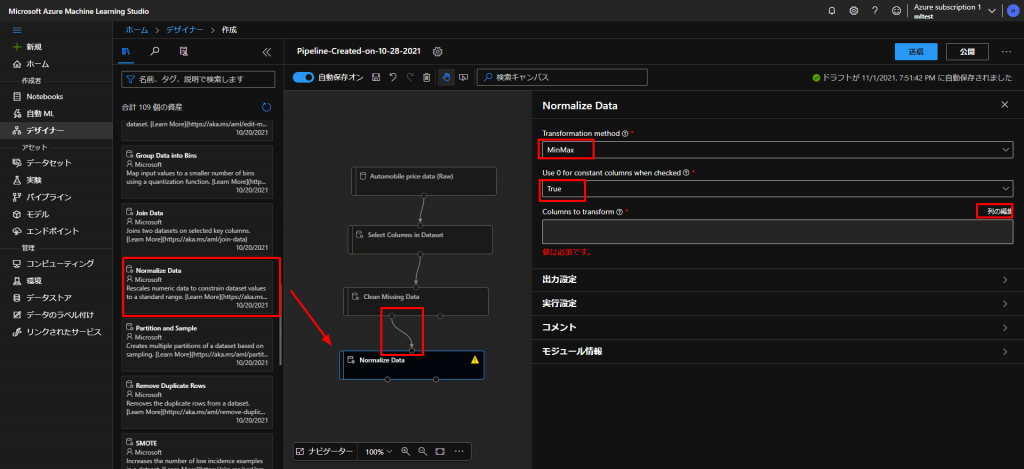
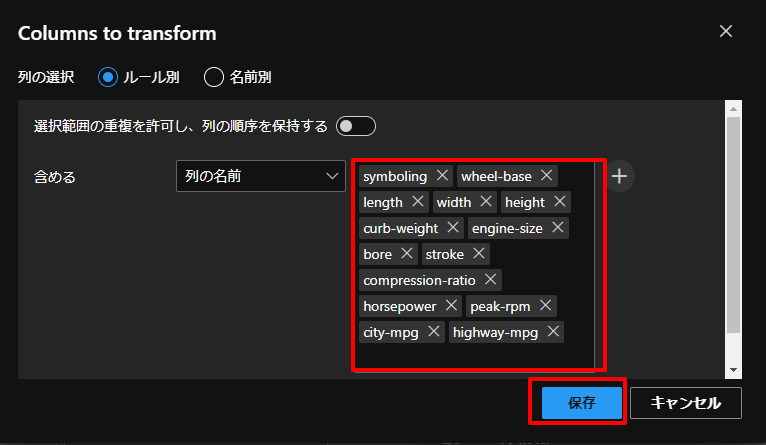
続いて、下図のように列を選択していきます。こちらは、文字列でない、数値のデータのみ選択していきます。
- STEP
データ分割
データがようやく整いましたので、こちらを機械学習していきたいのですが、すべてのデータを機械学習してしまうと、検証できなくなりますので、学習用データとテストデータという形で、データベースを分割していきます。
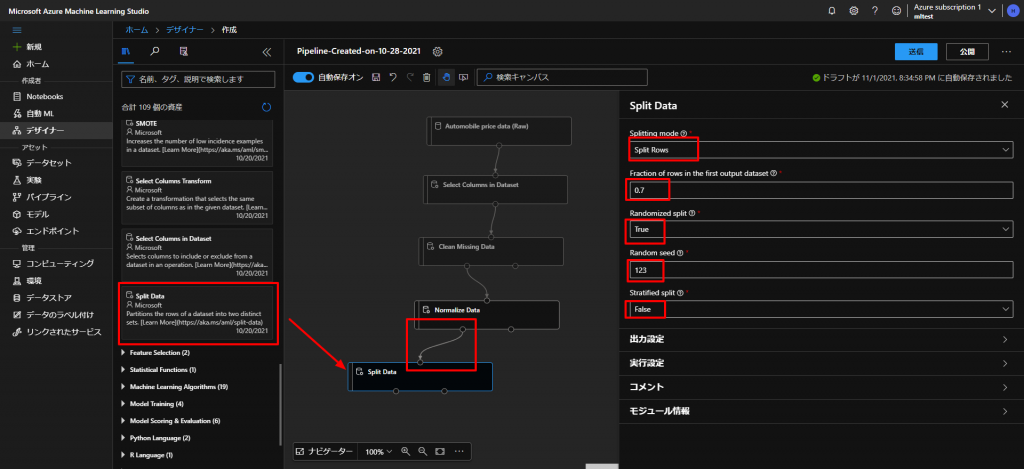
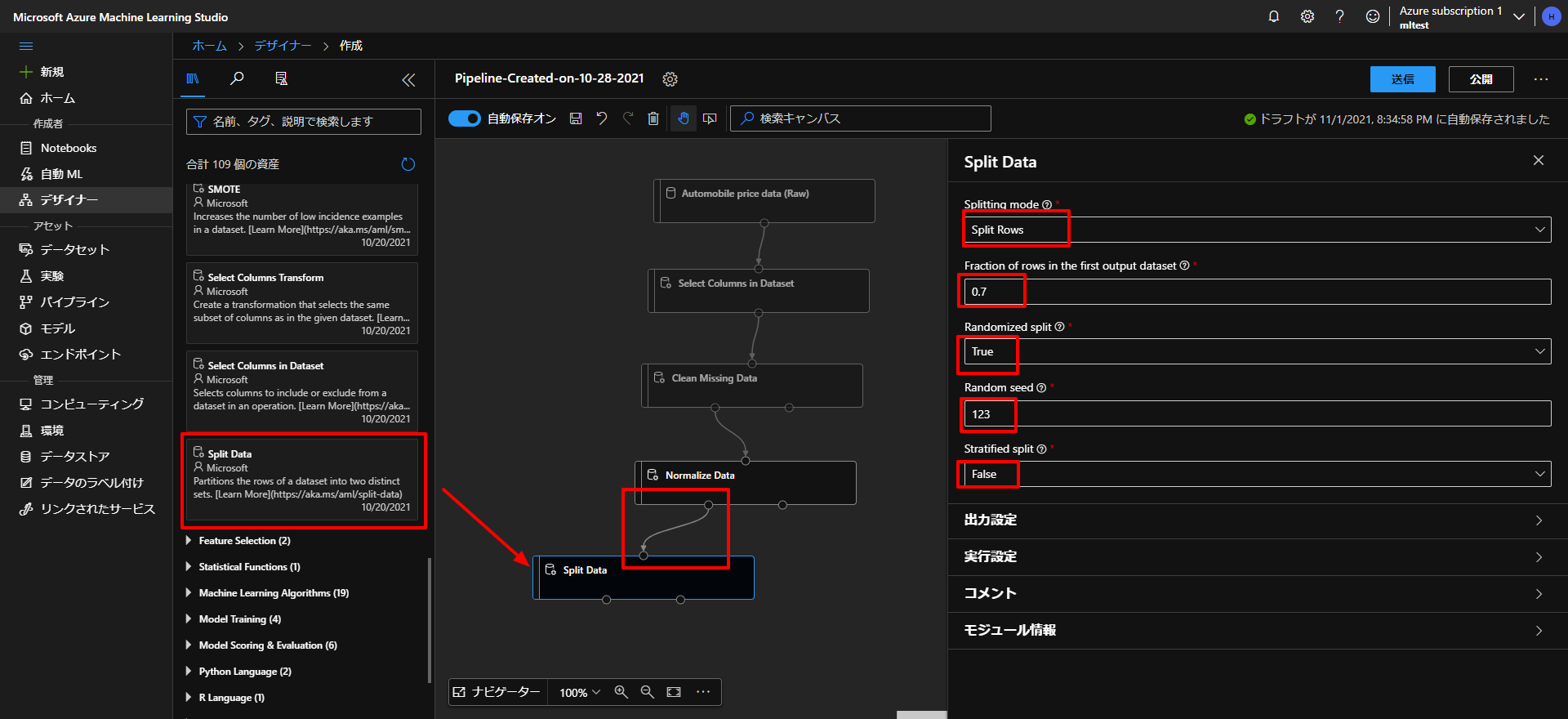
上図のように、 Data Transfomation からSplit Dataをドラッグアンドドロップして、上とつなぎます。
また、各種設定を、Splitting modeをSplit Rows、Fraction of rows in the first output datasetを0.7、Randomized splitをTrue、Random seedを123、Stratified splitをFalseとします。
- STEP
モデルのトレーニング
これで、ようやく機械学習のモデルの設定をしていきます。
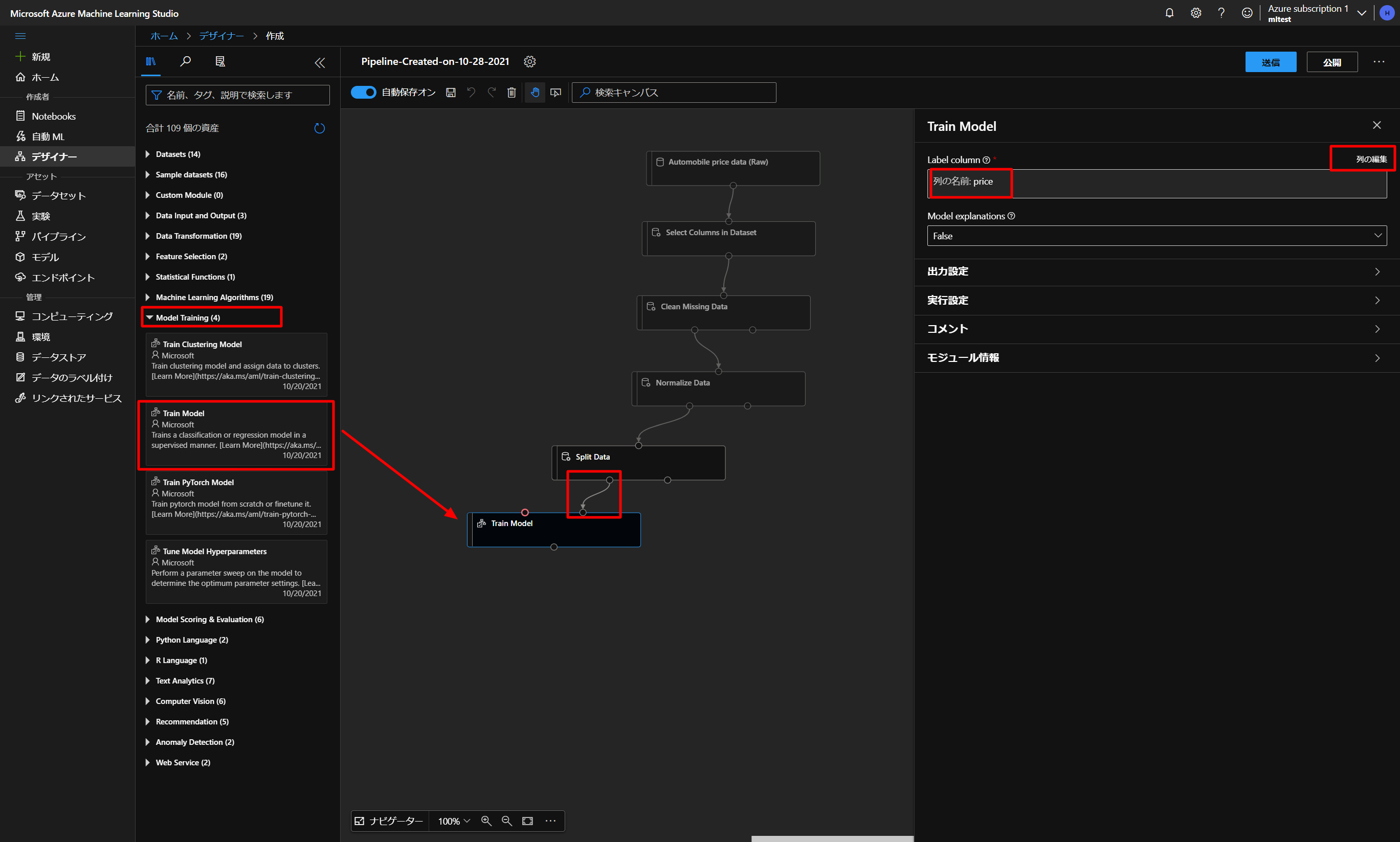
下図のように、Model Trainingの中からTrain Modelをドラッグアンドドロップして、上のブロックの左のポイントと、右上のポイントをつないでいきます。
そして、画面右のLabel columnで列の編集をクリックして、今回予測したいPriceに設定しておきます。
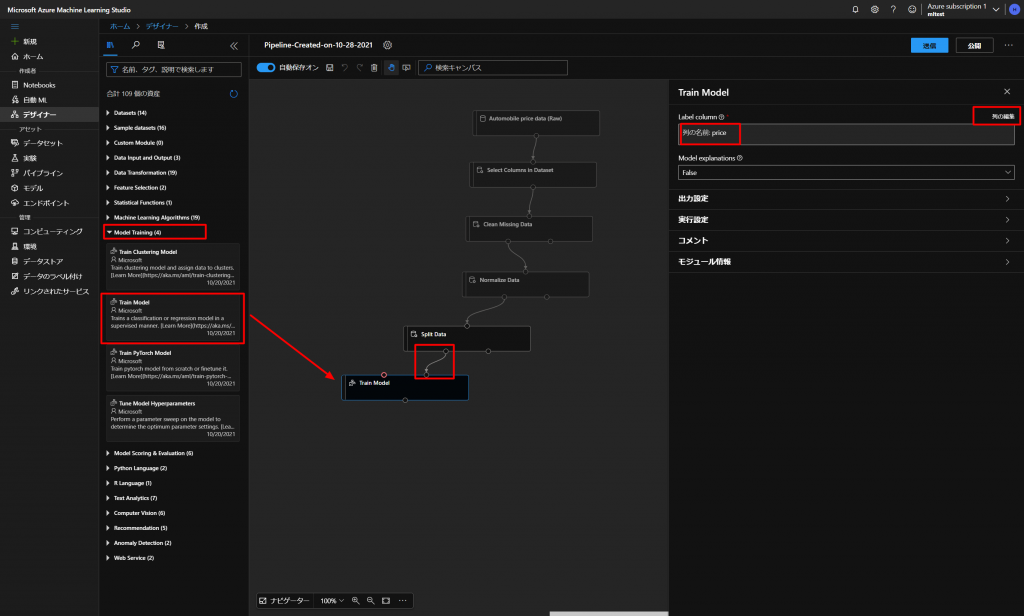
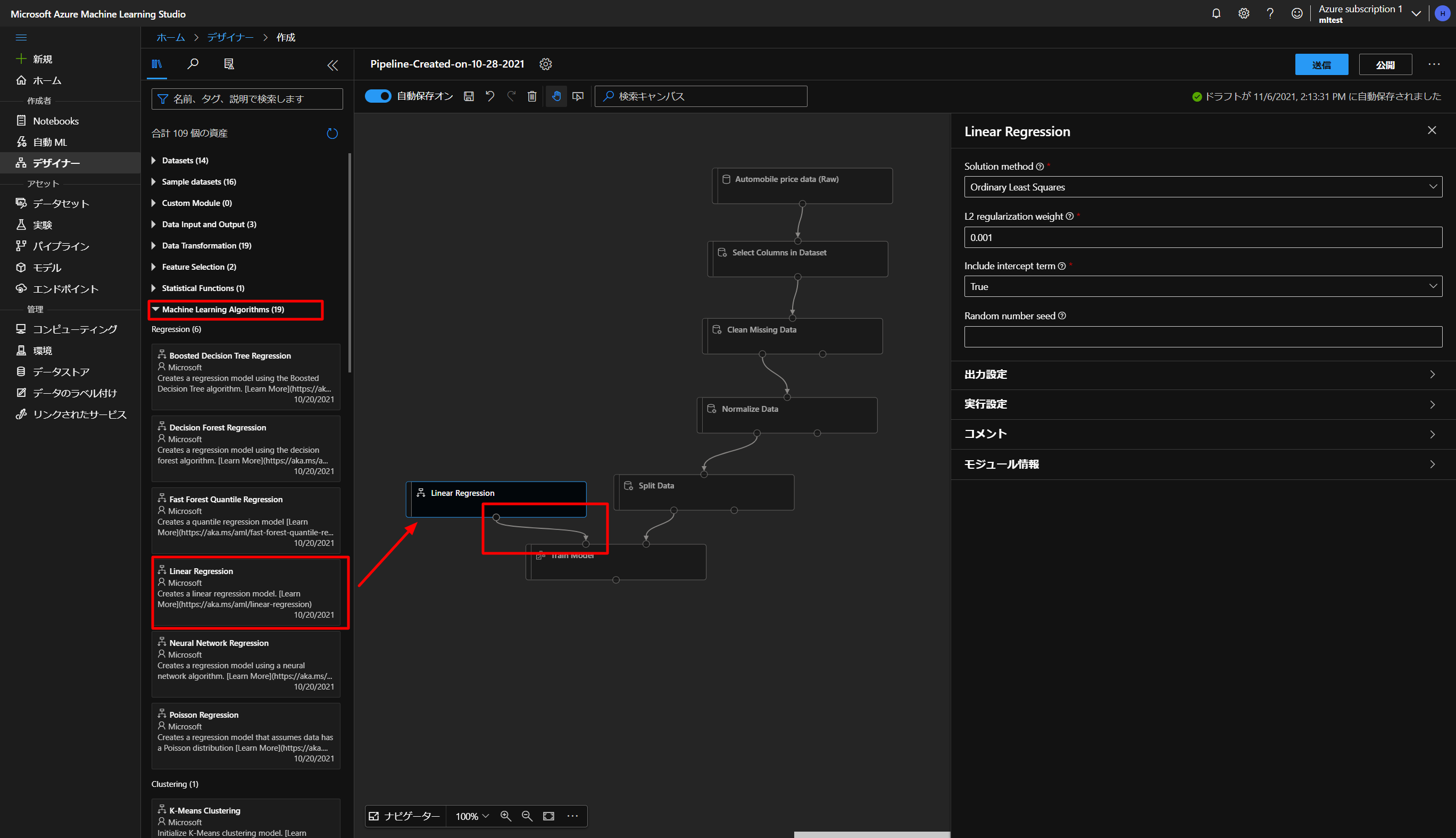
続いて、トレーニングするアルゴリズムを選択していきます。
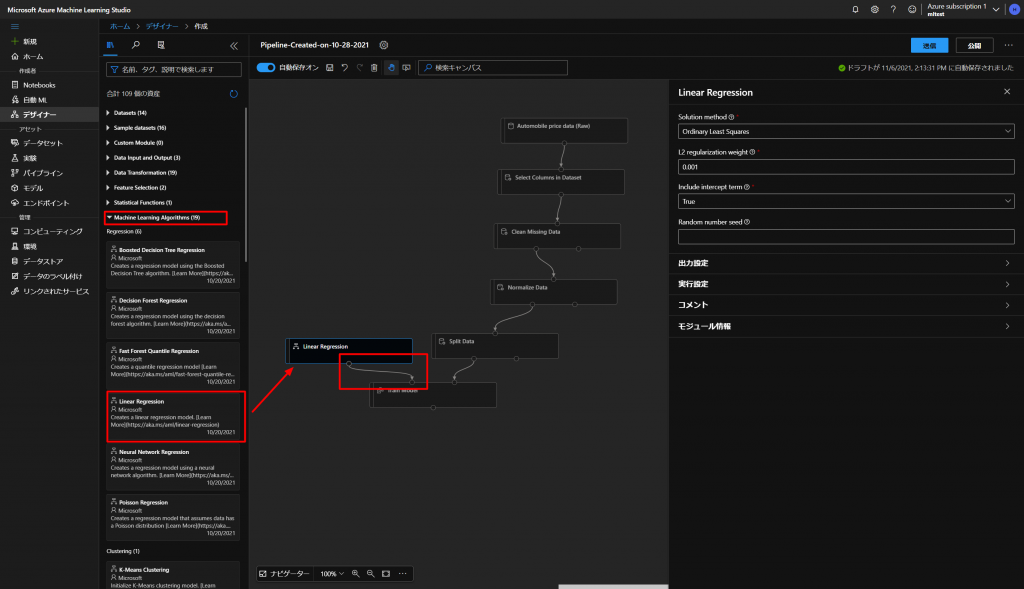
上図のように、Machine Learning AlgorithmsからLinear Regression(線形回帰)を選択していきます。
Train Modelのブロックの左上のポイントとつなぎます。
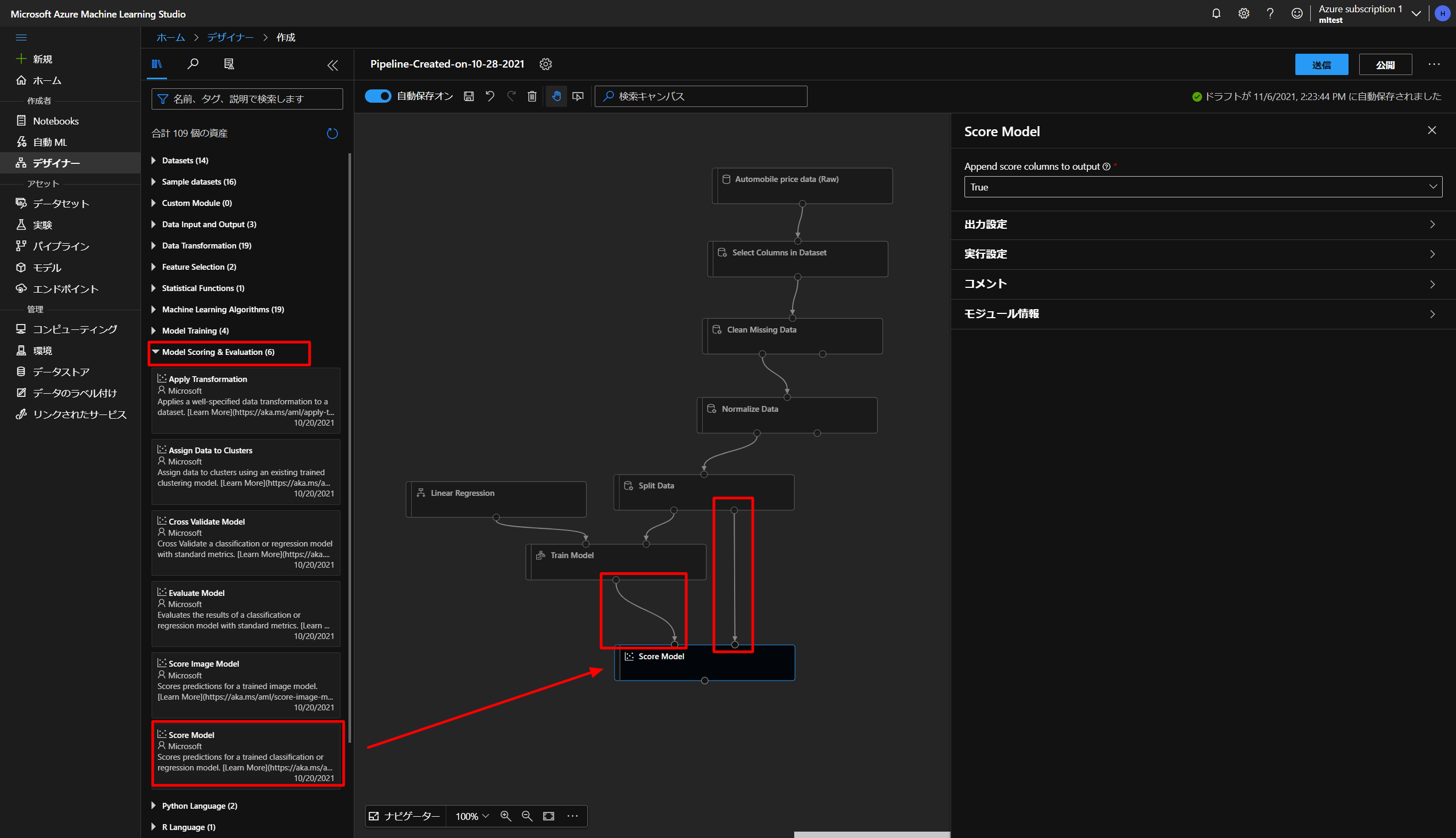
そして、最後にこちらのモデルの検証をするために、下図のようにModel Scoring & EvaluationからScore Modelをドラッグアンドドロップして、図のようにつないでいきます。
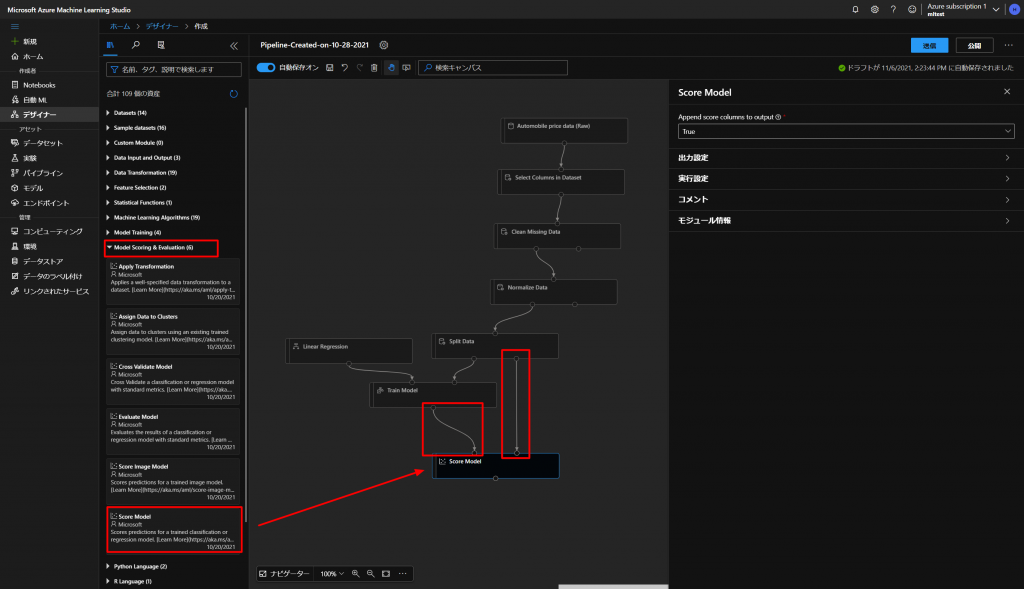
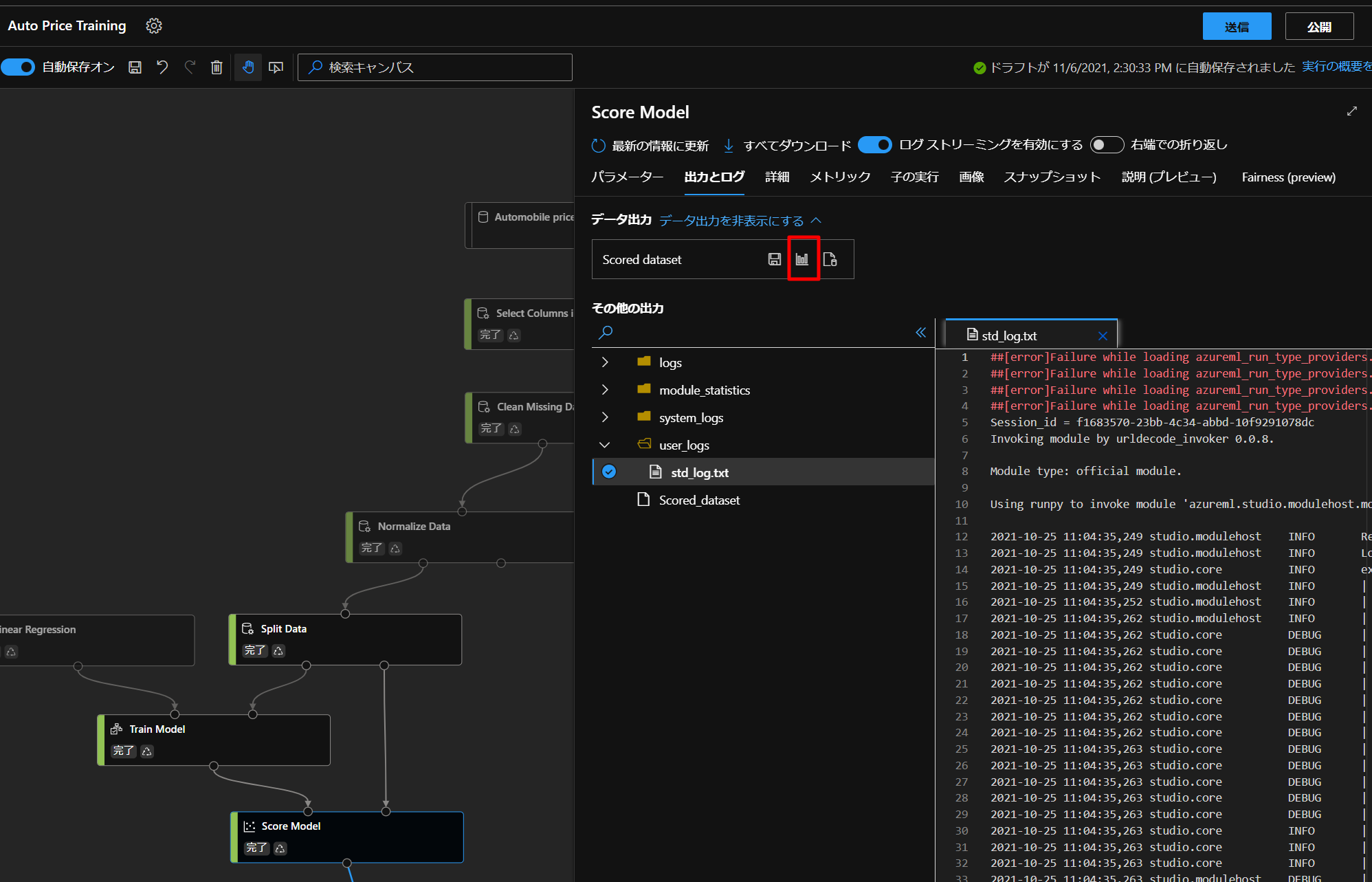
こちらを実行して、データの状態を一度確認していきます。
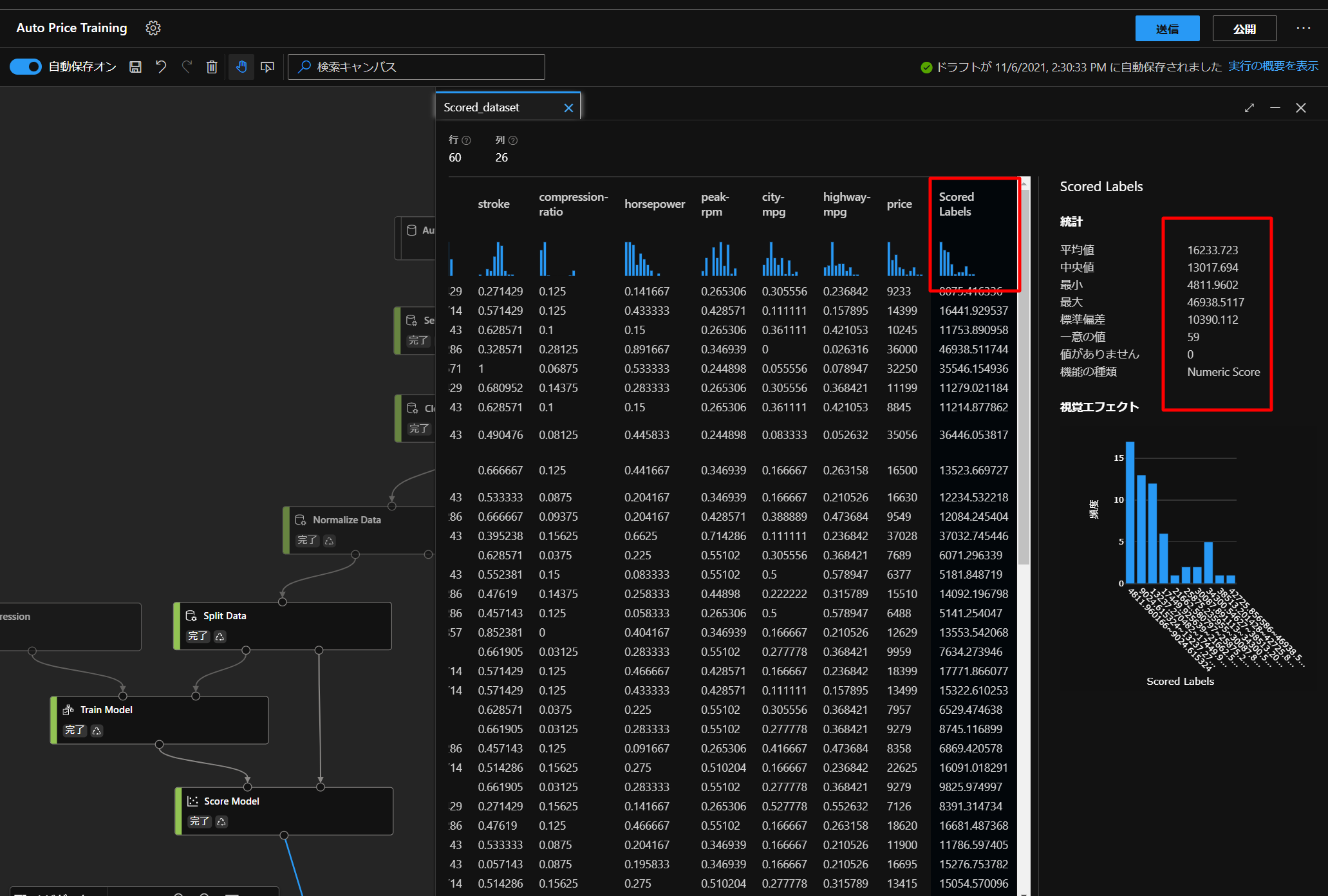
上図の通り、グラフのボタンをクリックして、データの詳細を確認していきます。
すると、Scored Labelsという列が追加されていることが分かります。
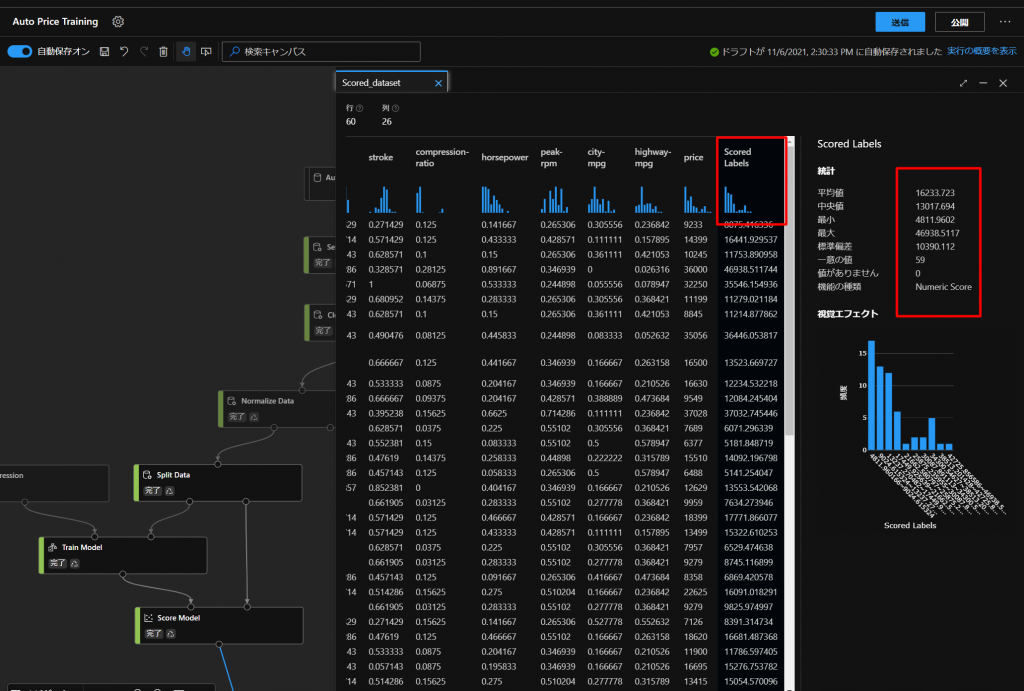
実際の価格とtrainingした価格を比較することができます。
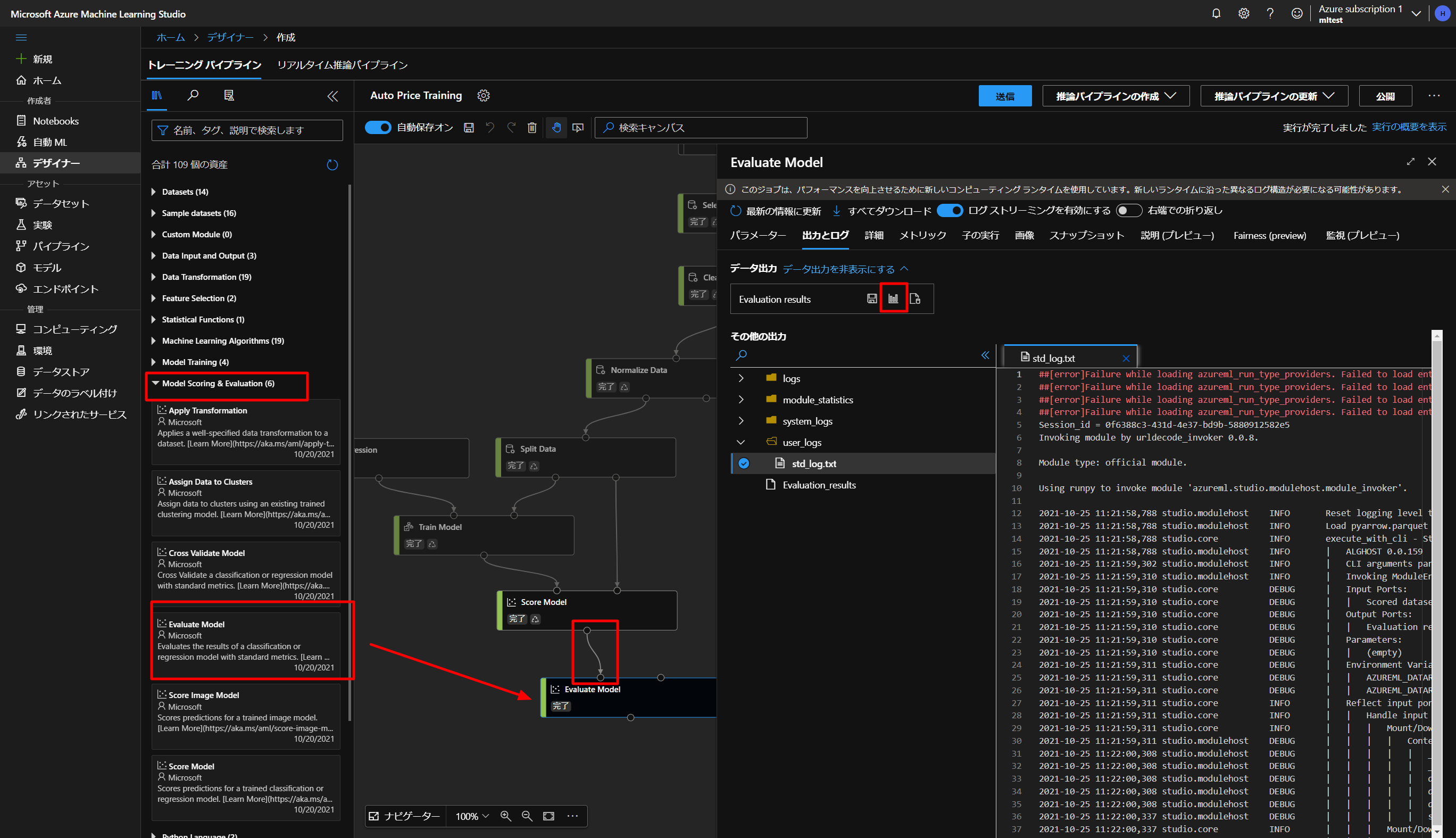
次に、上図の通り、スコアの評価をしていきます。
Model Scoring & EvaluationからEvaluate Modeをドラッグアンドドロップして、上とつないでいき、再度実行します。
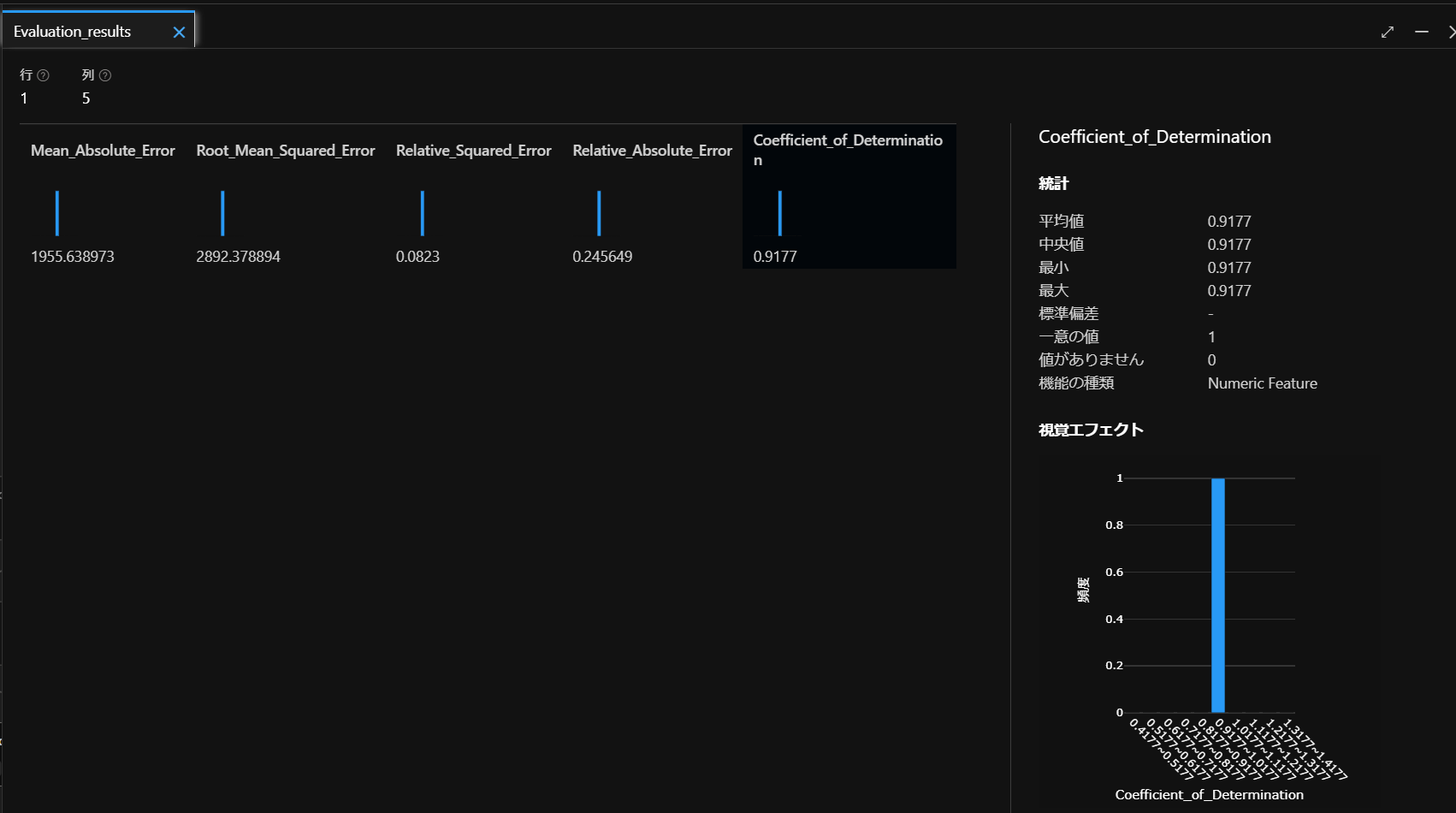
そうしたら、上図のように、グラフのマークをクリックして状態を確認します。
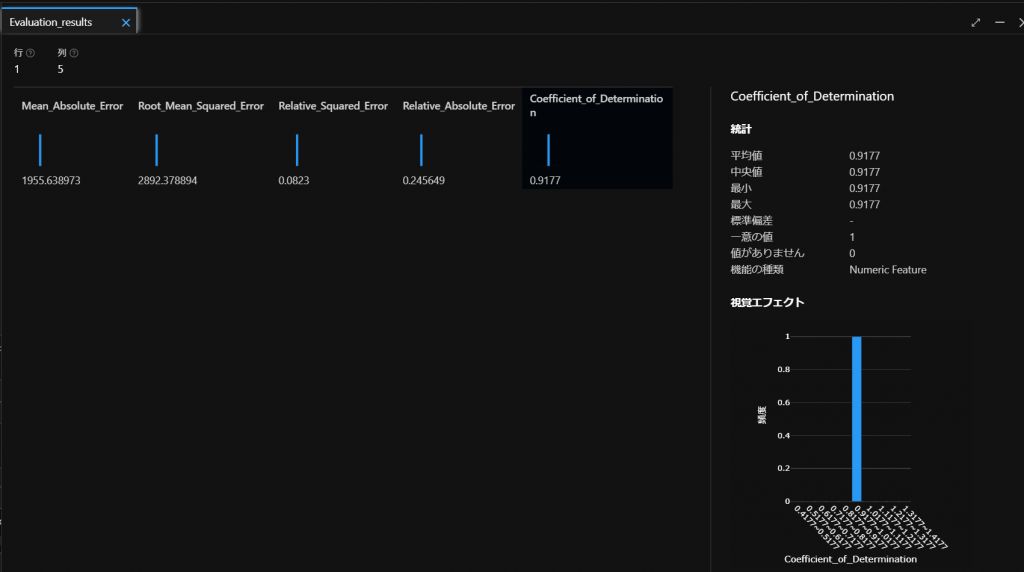
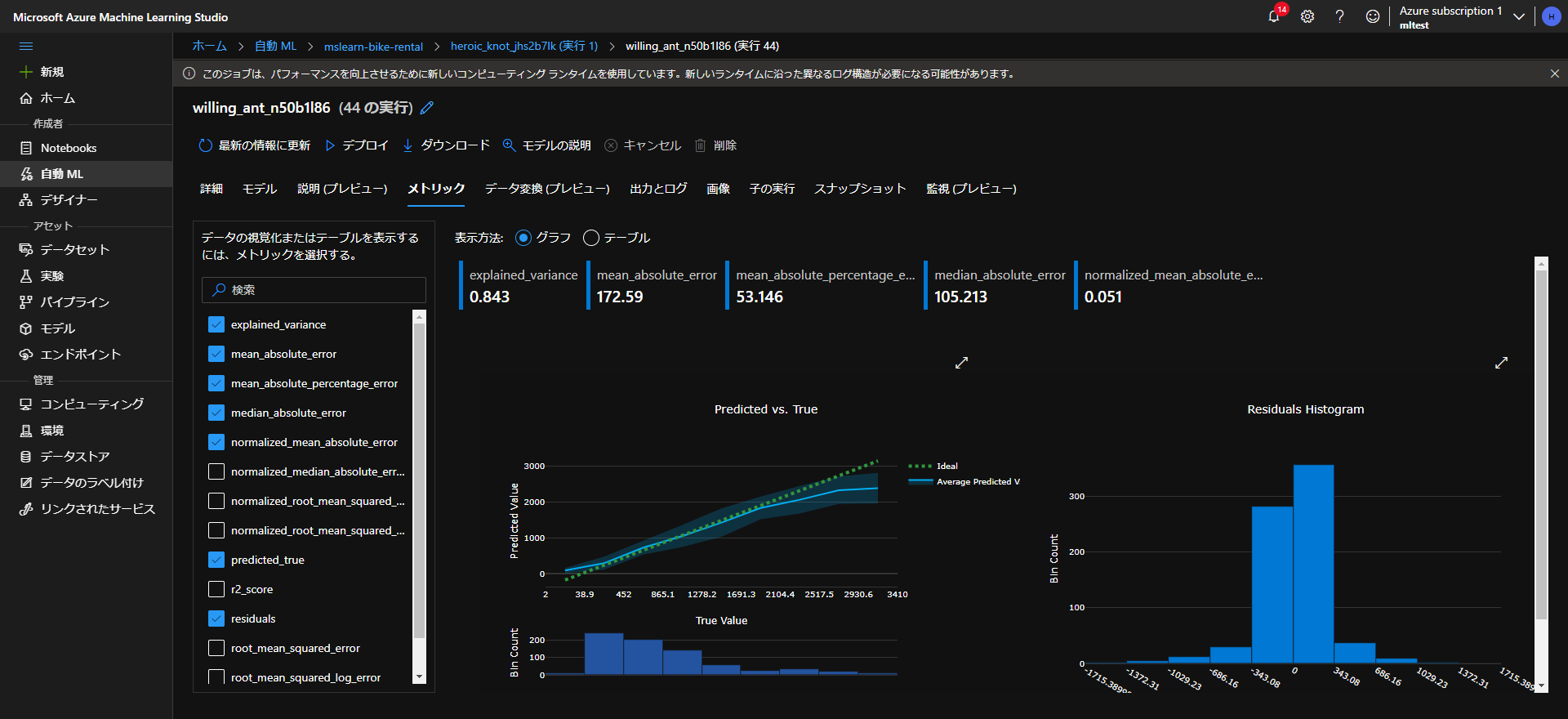
すると、上図のように5つの評価指標が出てきます。
こちらは以下の評価基準を参考にしてモデルの状態を確認していきます。
項目 説明 Mean_Absolute_Error
平均絶対誤差 (MAE)予測値と真の値の差の平均。 この値は、ラベルと同じ単位 (この例ではドル) に基づいています。 この値が小さいほど、モデルの予測が正確です。 Root_Mean_Squared_Error
二乗平均平方根誤差 (RMSE)予測と真の値の平均二乗の平方根の差。 結果は、ラベルと同じ単位 (ドル) に基づくメトリックになります。 MAE (上記) と比較すると、差が大きいほど個々の誤差の分散が大きくなることを示します (たとえば、一部の誤差が非常に小さく、他の誤差が大きい場合など)。 Relative_Squared_Error
相対二乗誤差 (RSE)予測と真の値の差の 2 乗に基づく、0 から 1 の間の相対的なメトリック。 このメトリックが 0 に近いほど、モデルのパフォーマンスが高くなります。 このメトリックは相対的なものであるため、ラベルの単位が異なるモデルを比較するために使用できます。 Relative_Absolute_Error
相対絶対誤差 (RAE)予測と真の値の絶対差に基づく、0 から 1 の間の相対的なメトリック。 このメトリックが 0 に近いほど、モデルのパフォーマンスが高くなります。 RSE と同様に、このメトリックは、ラベルの単位が異なるモデルを比較するために使用できます。 Coefficient_of_Determination
決定係数 (R2)このメトリックは、通常は “R-2 乗” と呼ばれ、予測と真の値の間の分散の量がモデルによって説明される方法を要約します。 この値が 1 に近いほど、モデルのパフォーマンスが高くなります。 今回は、適当なモデルをそのまま使いますので評価については割愛します。
- STEP
推論用のフロー作成
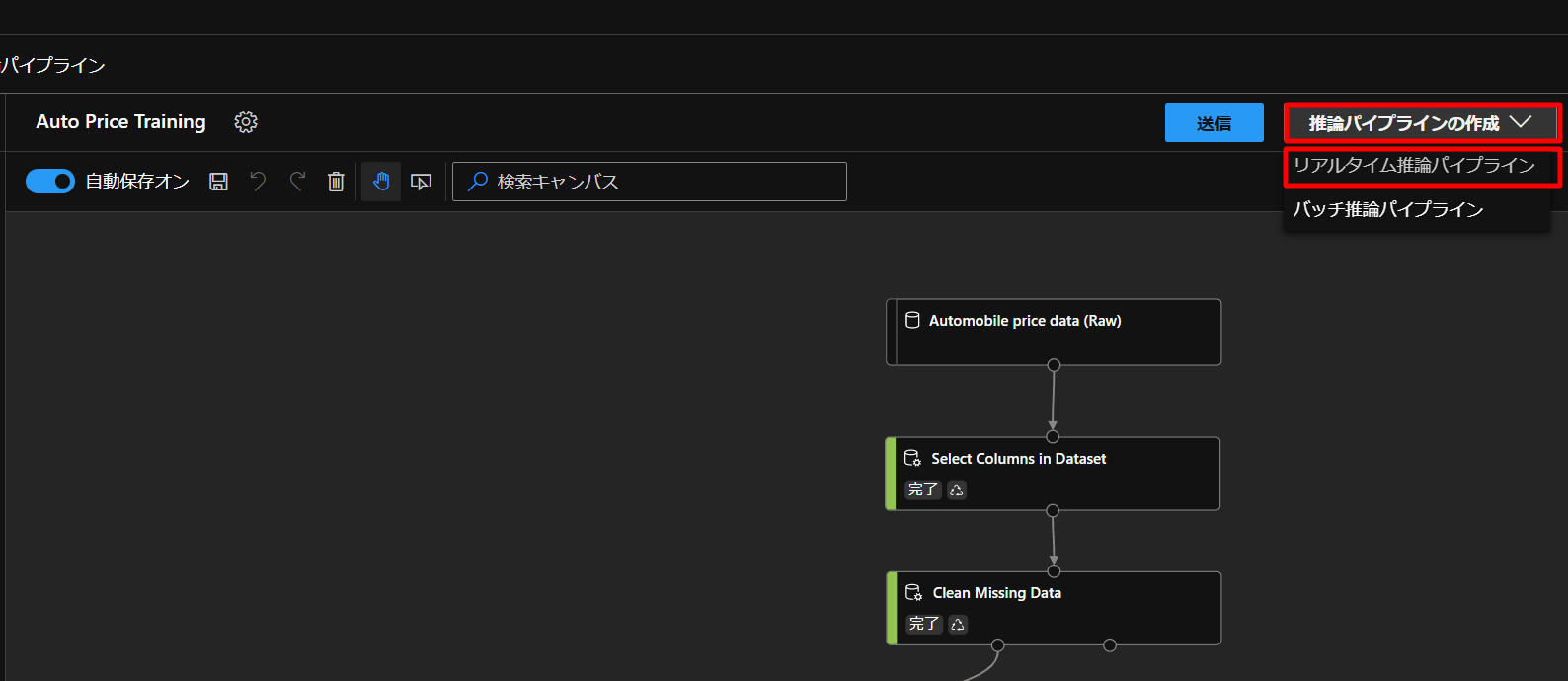
STEP6までで作ったモデルを実際に使えるようなフローを構築していきます。
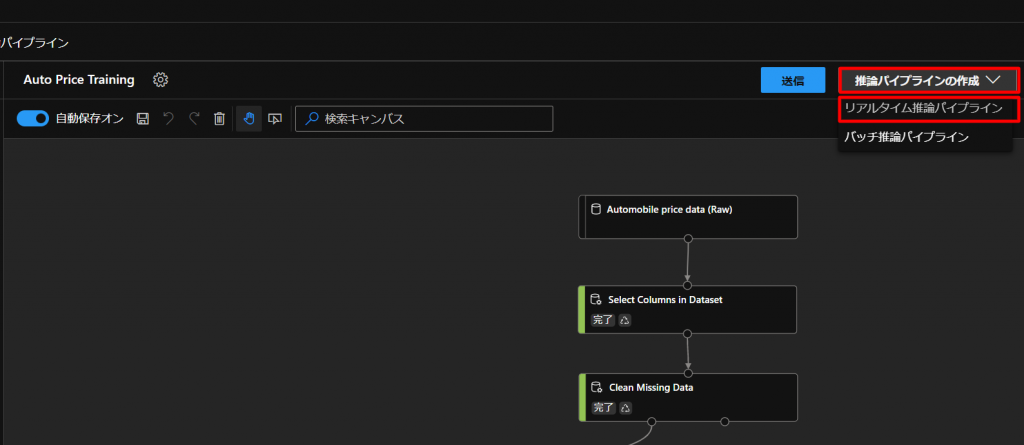
上図のように、現状のtrainingモデルの推論パイプラインの作成からリアルタイム推論パイプラインをクリックします。
すると、新しいフローができあがりますので、こちらを編集していきます。
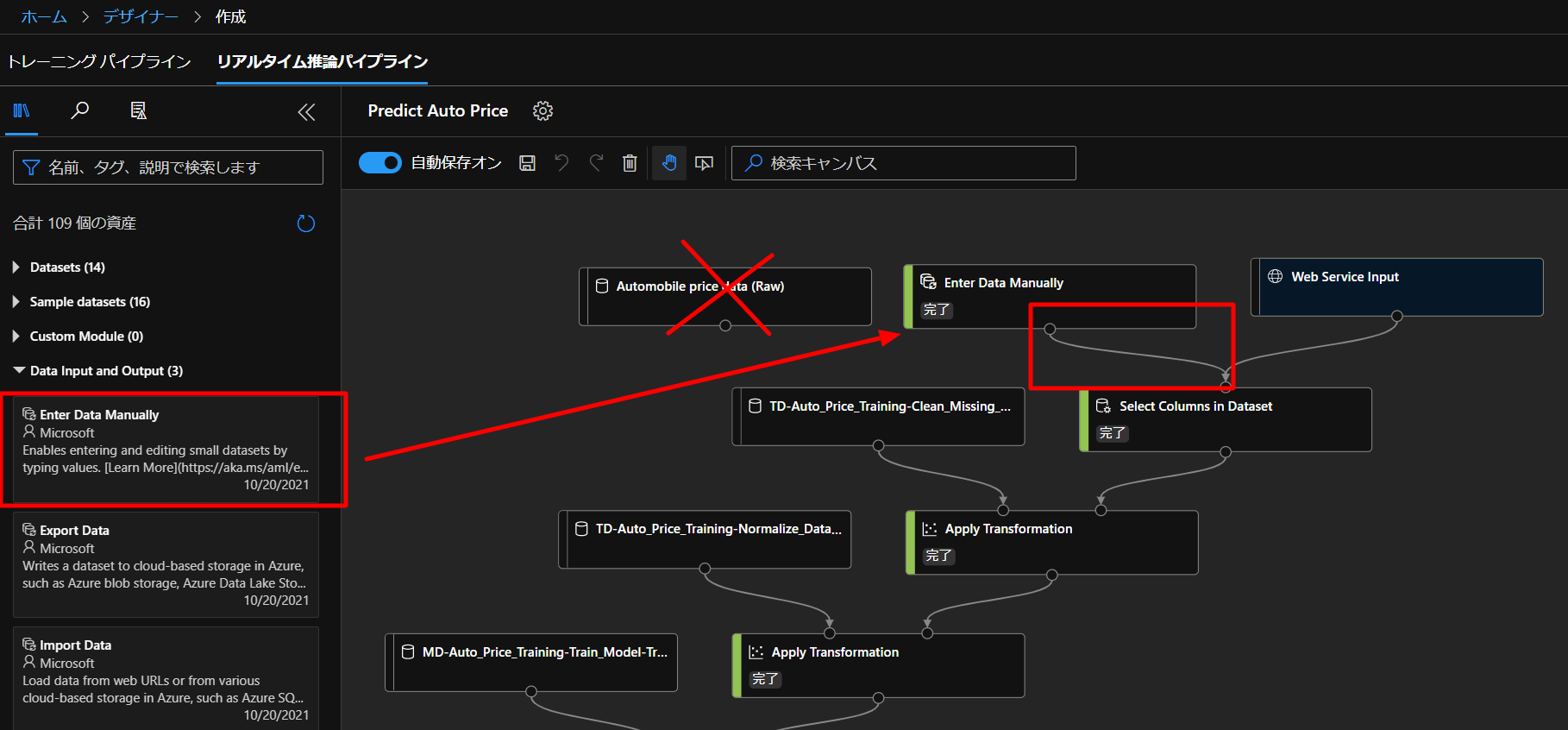
新しくできたフローを開いていくと、下図のようなフローが勝手にできあがりますので、こちらを編集していきます。
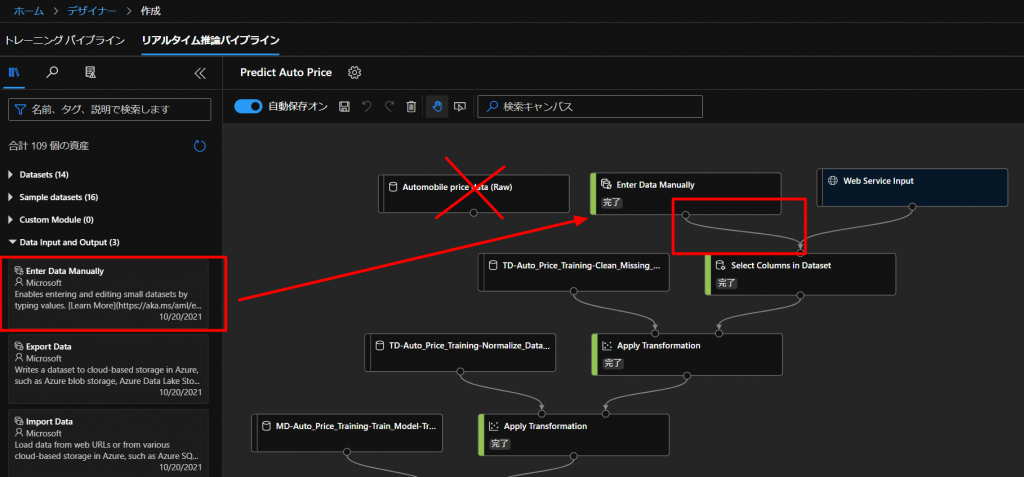
同じデータを使うのではなく、自分で用意したデータを入れていきたいので、上図のように、フローからAutomobile price data (Raw)を削除して、Data Input and OutputからEnter Data Manuallyをドラッグアンドドロップして、つないでいきます。
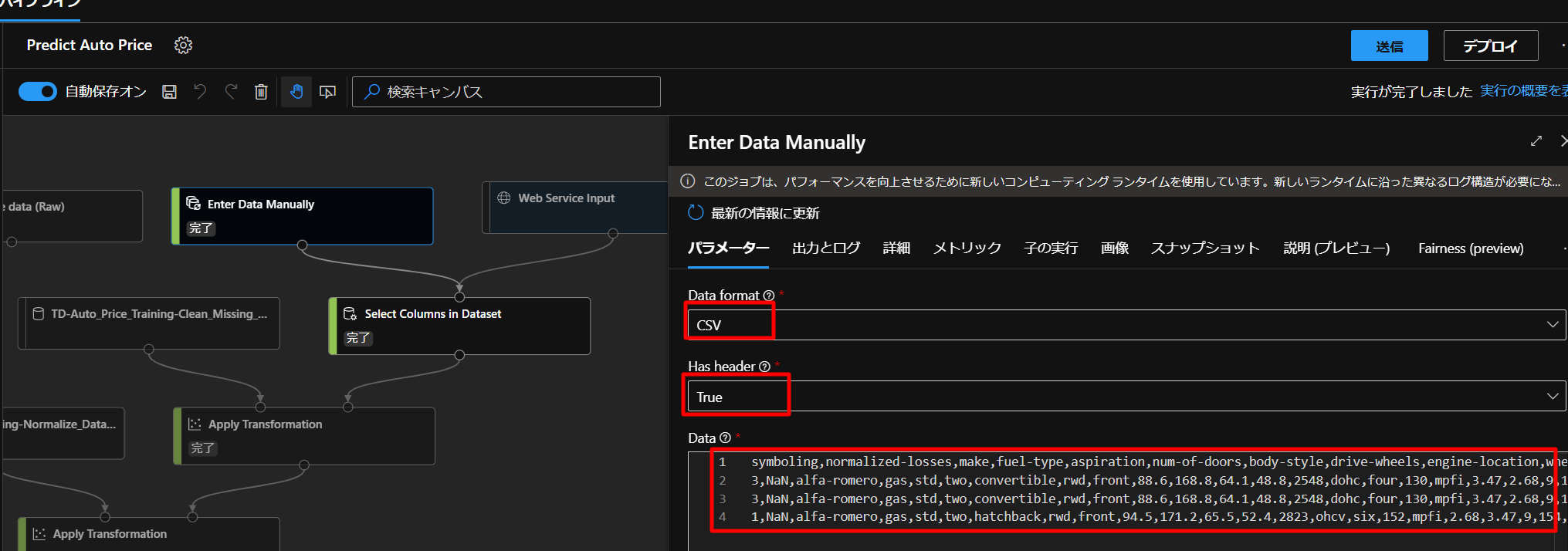
ここで、今回は、すでに用意してあるデータを入れていきますので、下図のように設定していきます。
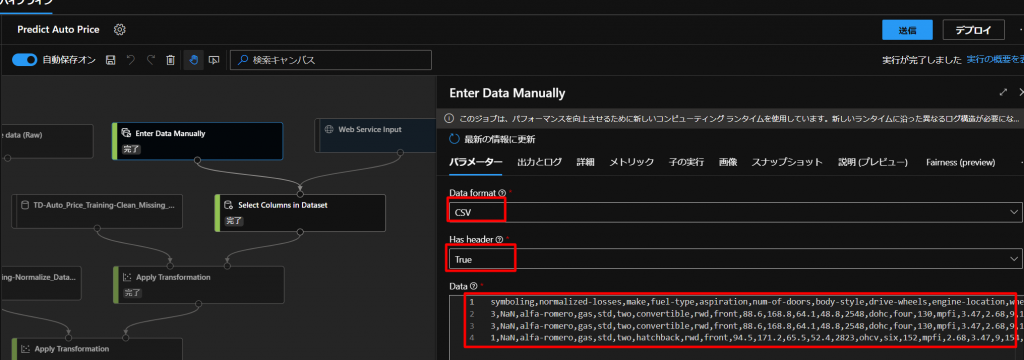
Data FormatをCSVにして、Has HeaderはTrueにして、以下のCSVデータをコピペします。
symboling,normalized-losses,make,fuel-type,aspiration,num-of-doors,body-style,drive-wheels,engine-location,wheel-base,length,width,height,curb-weight,engine-type,num-of-cylinders,engine-size,fuel-system,bore,stroke,compression-ratio,horsepower,peak-rpm,city-mpg,highway-mpg 3,NaN,alfa-romero,gas,std,two,convertible,rwd,front,88.6,168.8,64.1,48.8,2548,dohc,four,130,mpfi,3.47,2.68,9,111,5000,21,27 3,NaN,alfa-romero,gas,std,two,convertible,rwd,front,88.6,168.8,64.1,48.8,2548,dohc,four,130,mpfi,3.47,2.68,9,111,5000,21,27 1,NaN,alfa-romero,gas,std,two,hatchback,rwd,front,94.5,171.2,65.5,52.4,2823,ohcv,six,152,mpfi,2.68,3.47,9,154,5000,19,26もともと価格を予測することが目標だったので、こちらのデータにはPrice(価格)の列は含まれておりません。
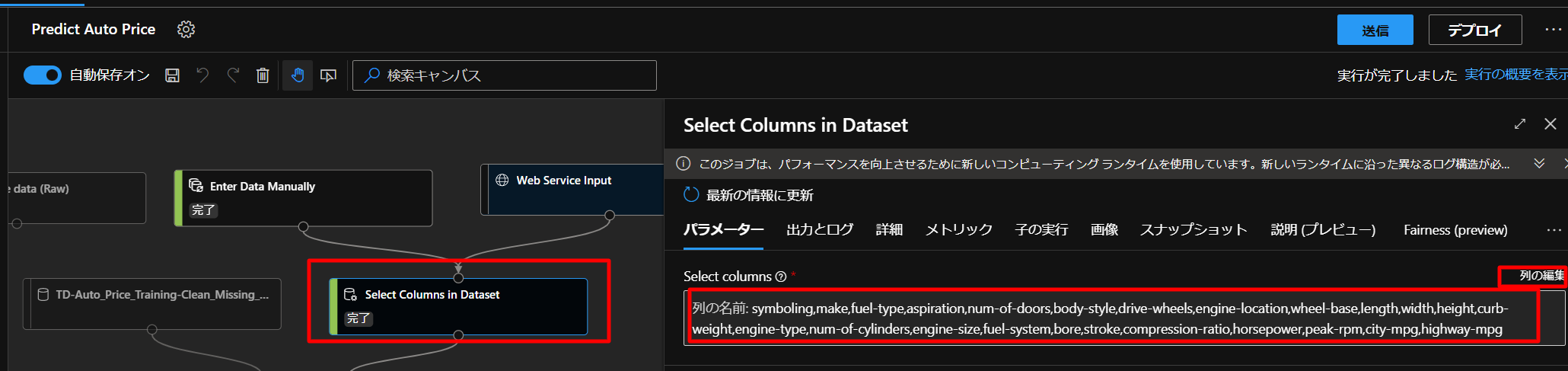
なので、データを使う列を再度編集します。
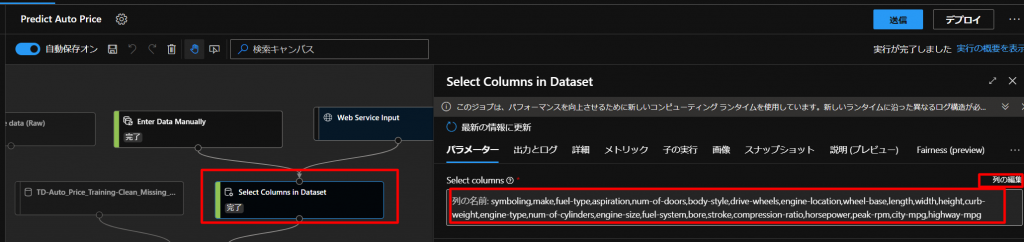
上図のように、Select Columns in Datasetのブロックで、列の編集からPriceを削除していきます。
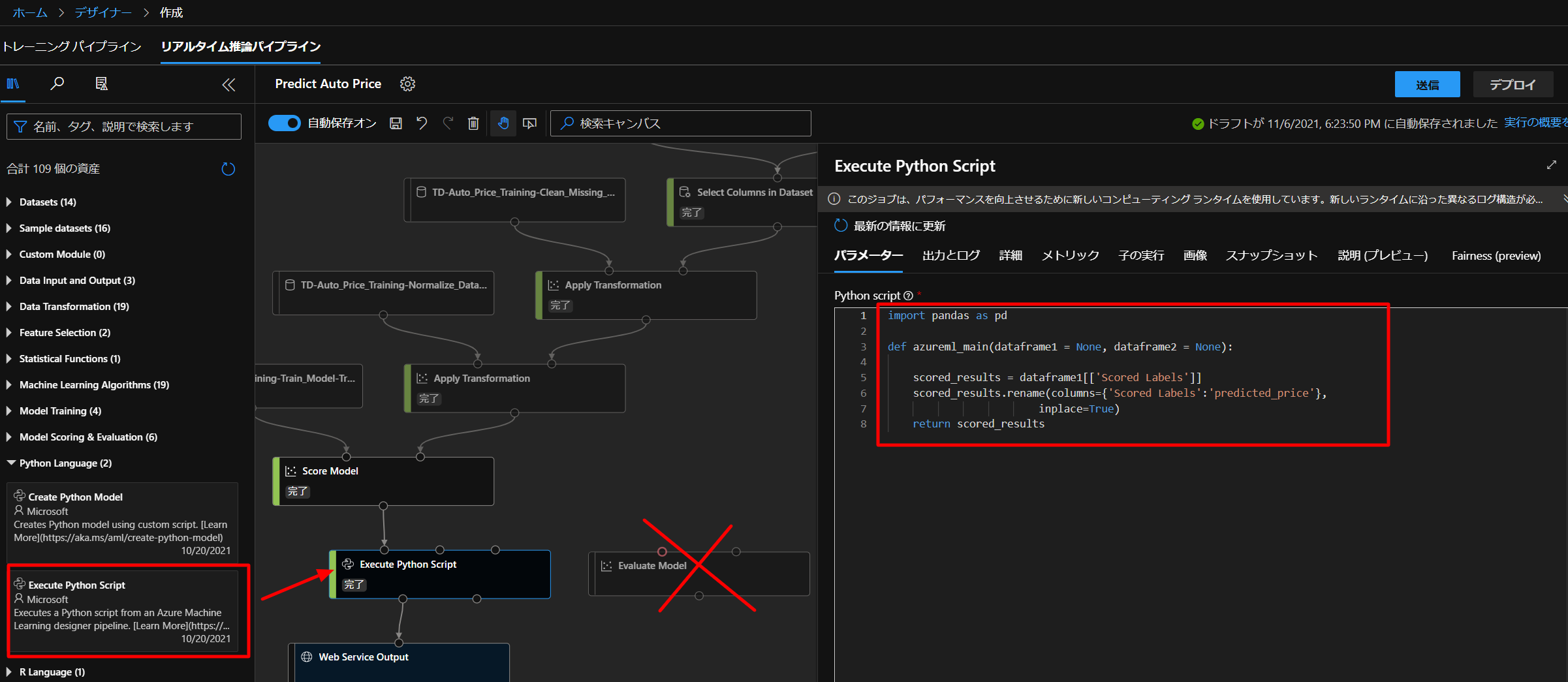
続いて、下図のように、モデルの評価は特に必要ないので、削除していき、代わりに、Python LanguageからExecute Python Scriptをドラッグアンドドロップして、つないでいきます。
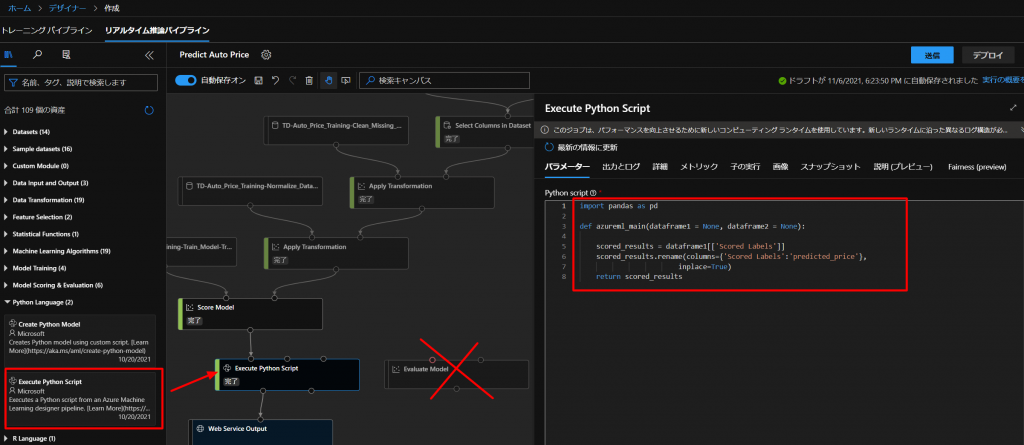
ここに、以下のコードに置き換えて、Scored Labelsの列をpredicted_priceという列の名前にリネームするコードを入れていきます。
import pandas as pd def azureml_main(dataframe1 = None, dataframe2 = None): scored_results = dataframe1[['Scored Labels']] scored_results.rename(columns={'Scored Labels':'predicted_price'}, inplace=True) return scored_resultsこれで、送信ボタンを押して実行していきます。
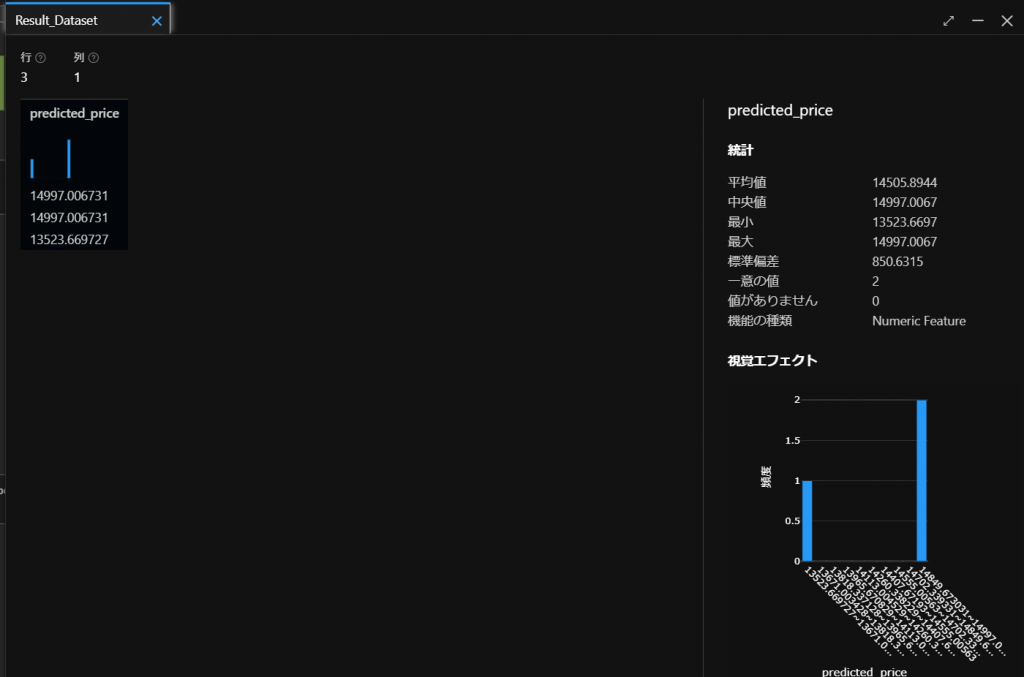
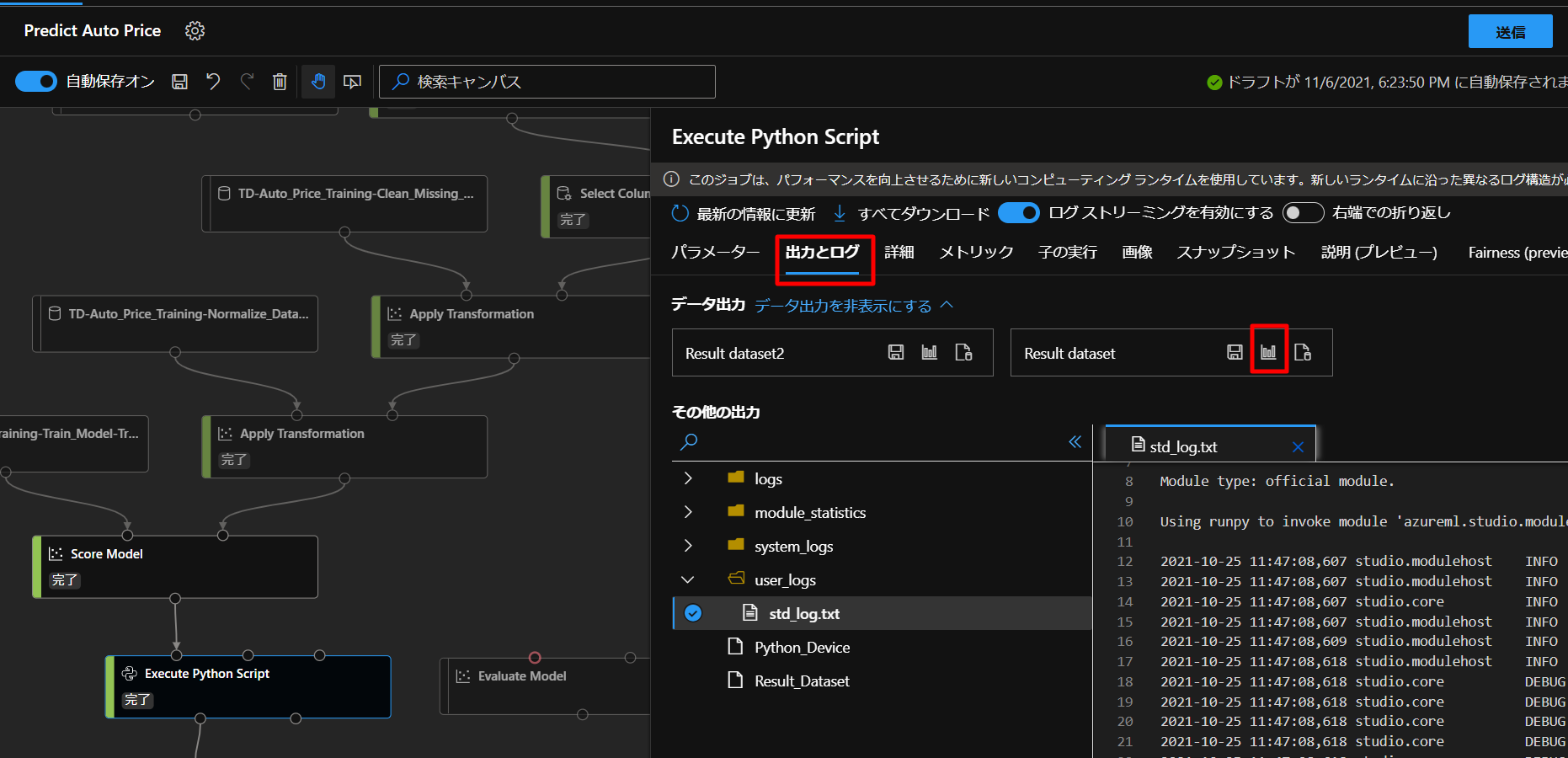
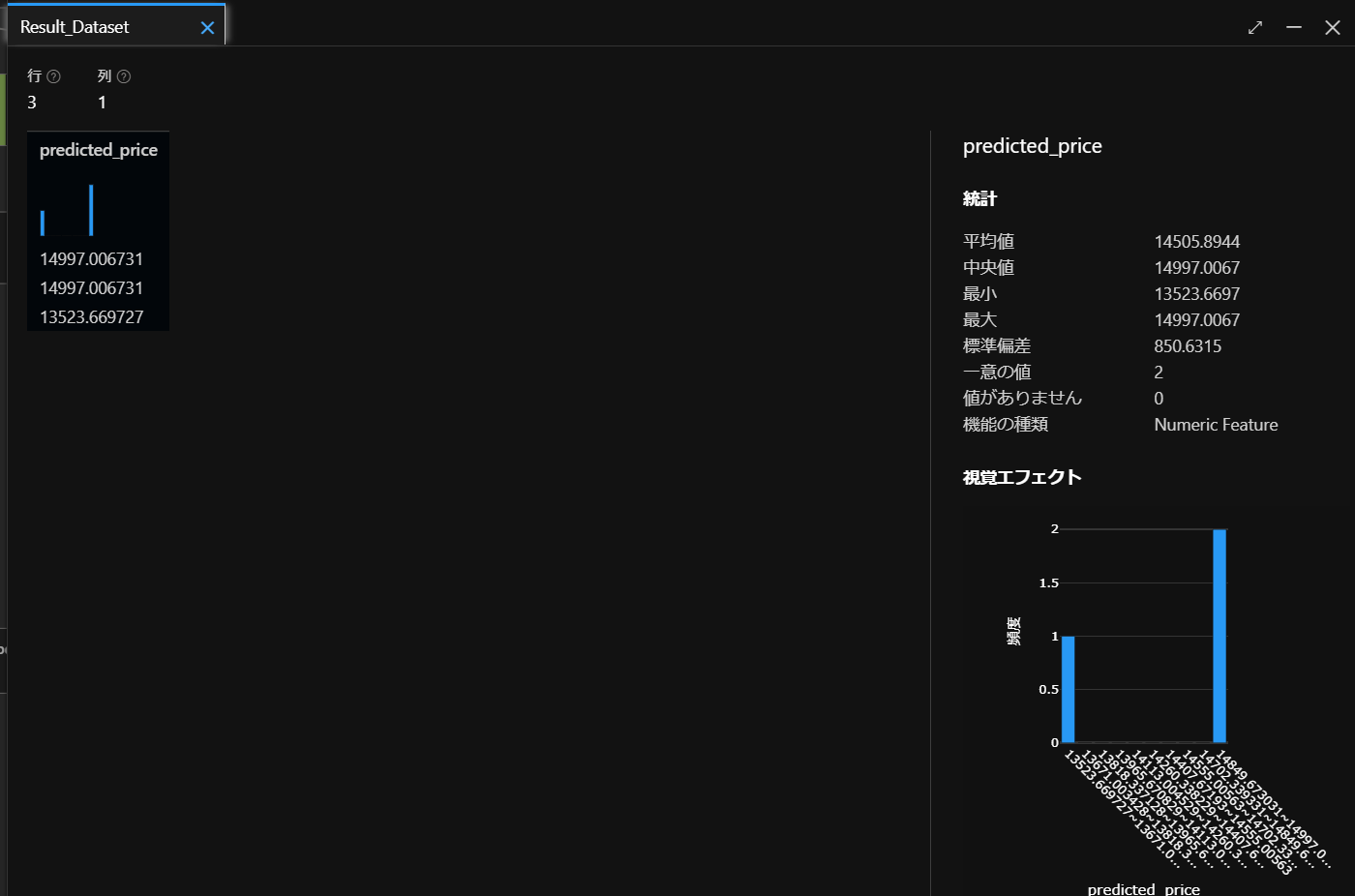
しばらく待つと結果が返ってきますので、下図のように、出力とログのタブからResult datasetのグラフをクリックします。
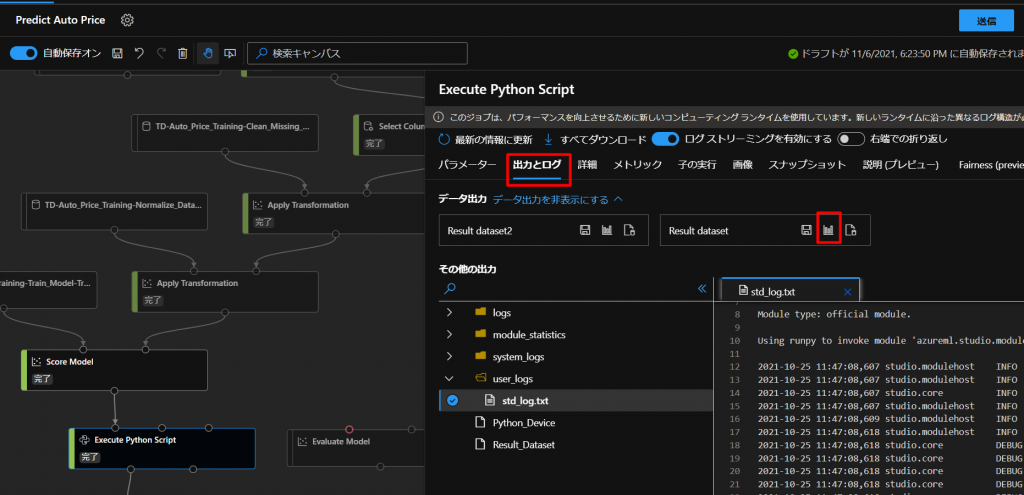
すると、下図のように、3つの値の結果(価格)が返ってきます。
- STEP
デプロイ
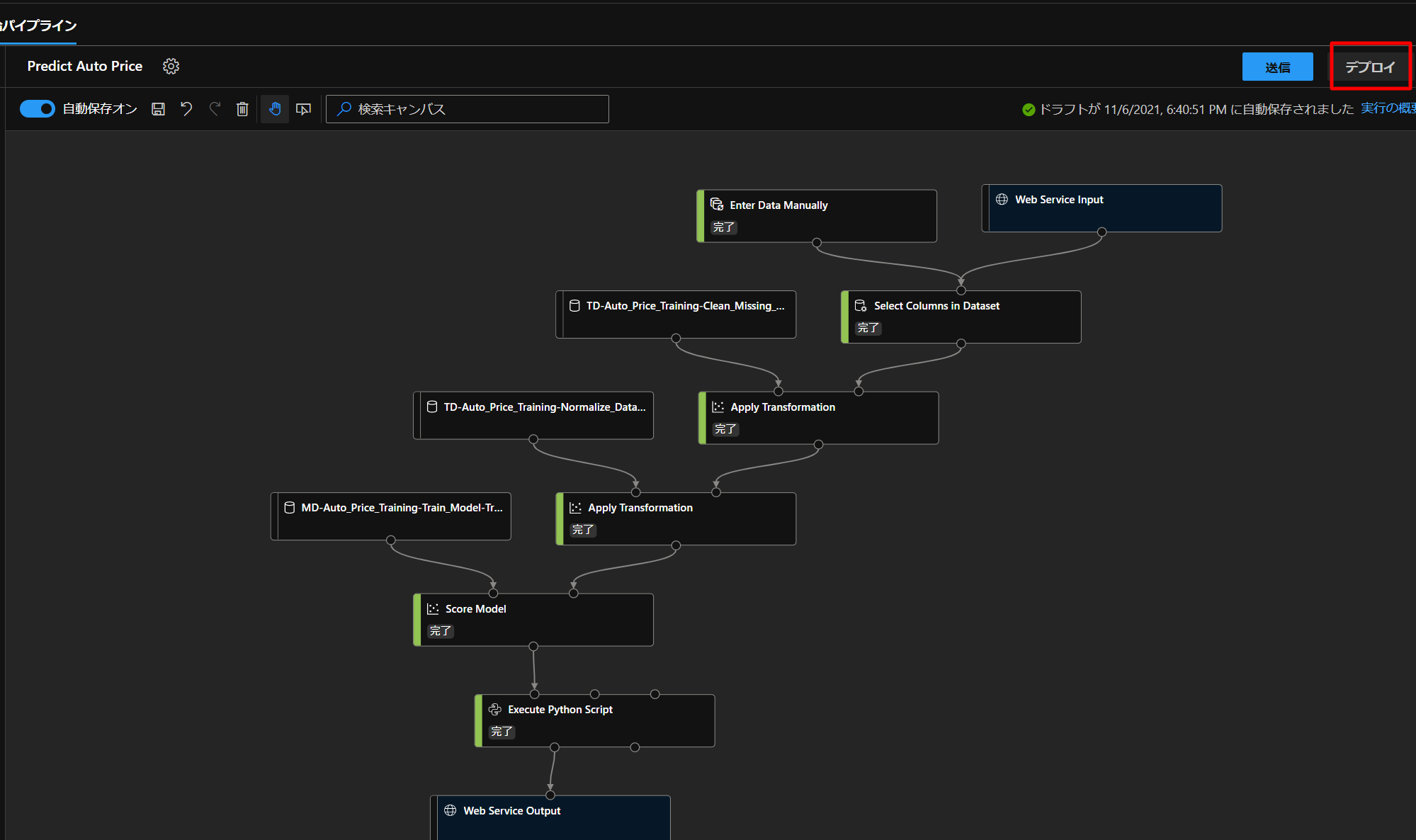
最後に、こちらのモデルを実際の環境などで使えるように、デプロイという作業を行っていきます。
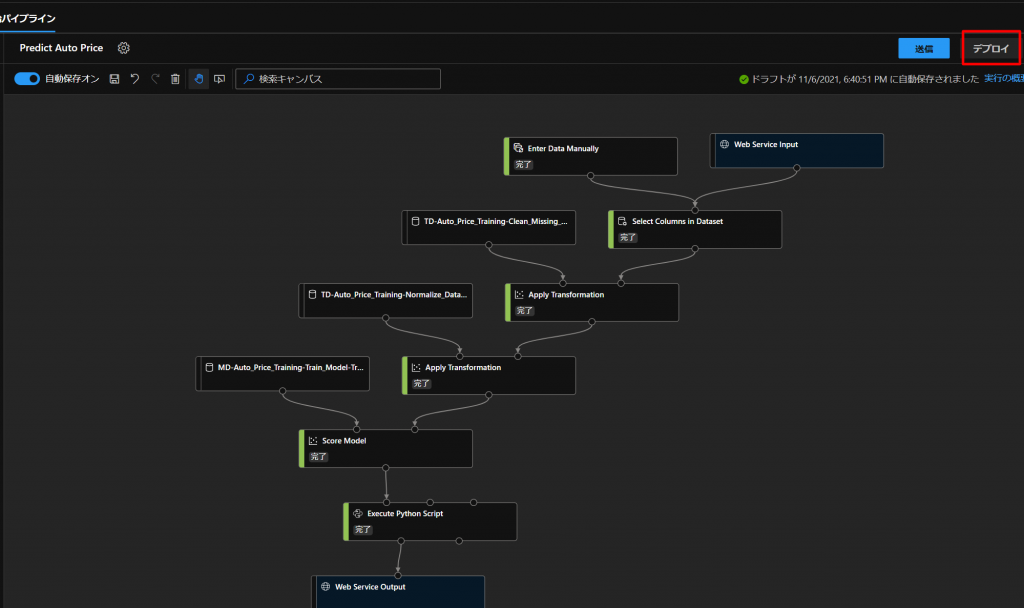
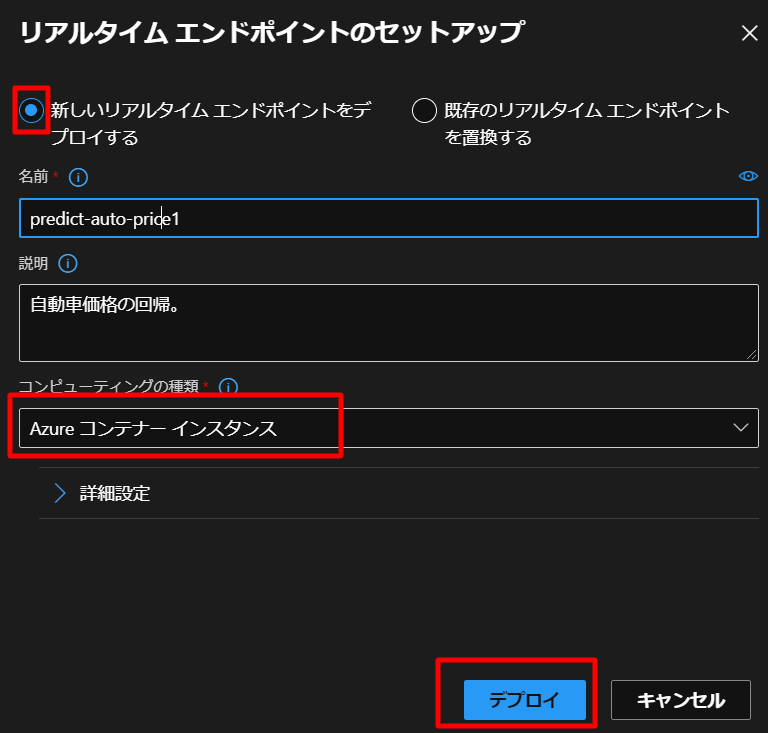
上図のように、デプロイをクリックして、下図のように設定します。
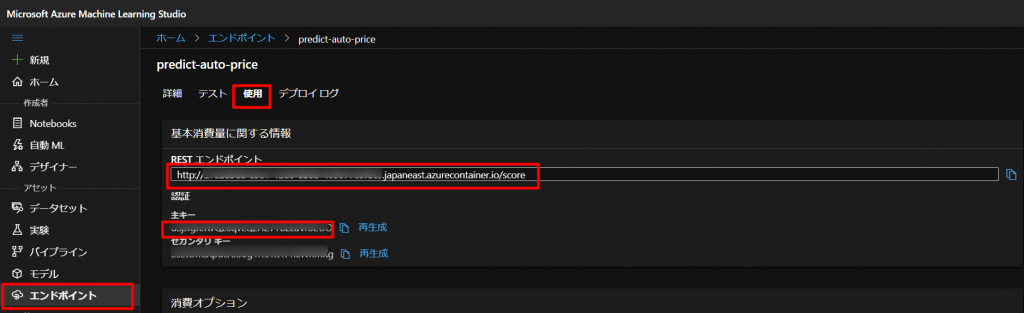
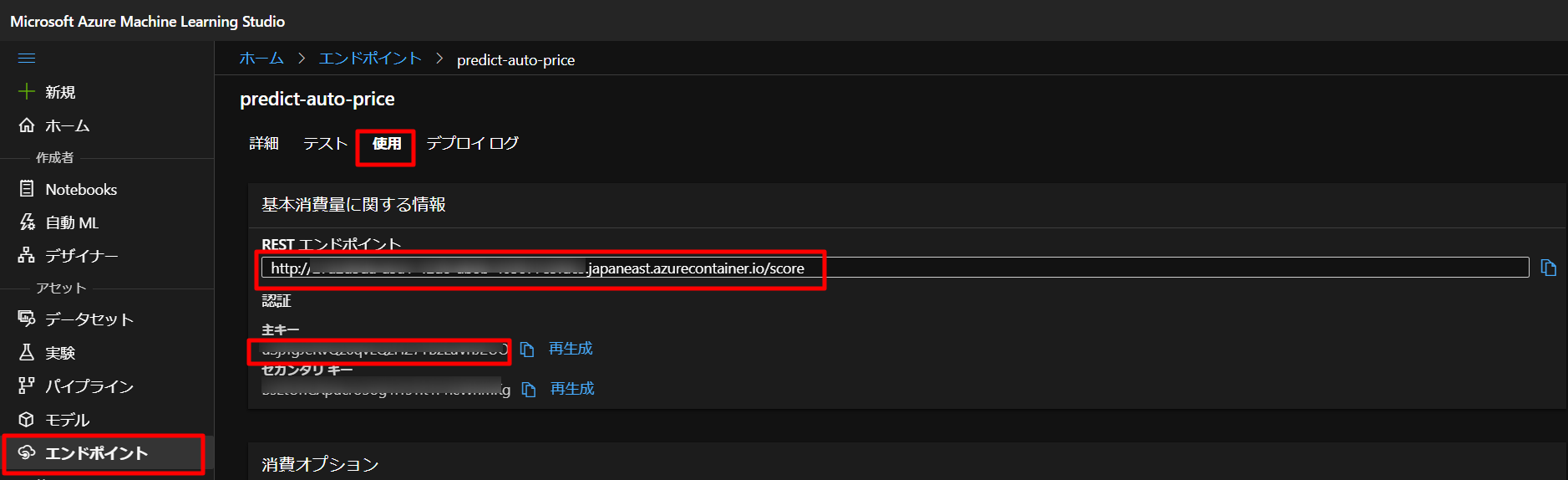
しばらく待ったら、エンドポイントというメニューに上記で設定した名前のエンドポイントが作成されますので、下図のように、使用タブでRESTエンドポイントと主キーが作成されているのを確認します。
- STEP
サービスとしてテスト
それでは最後にテストしていきます。
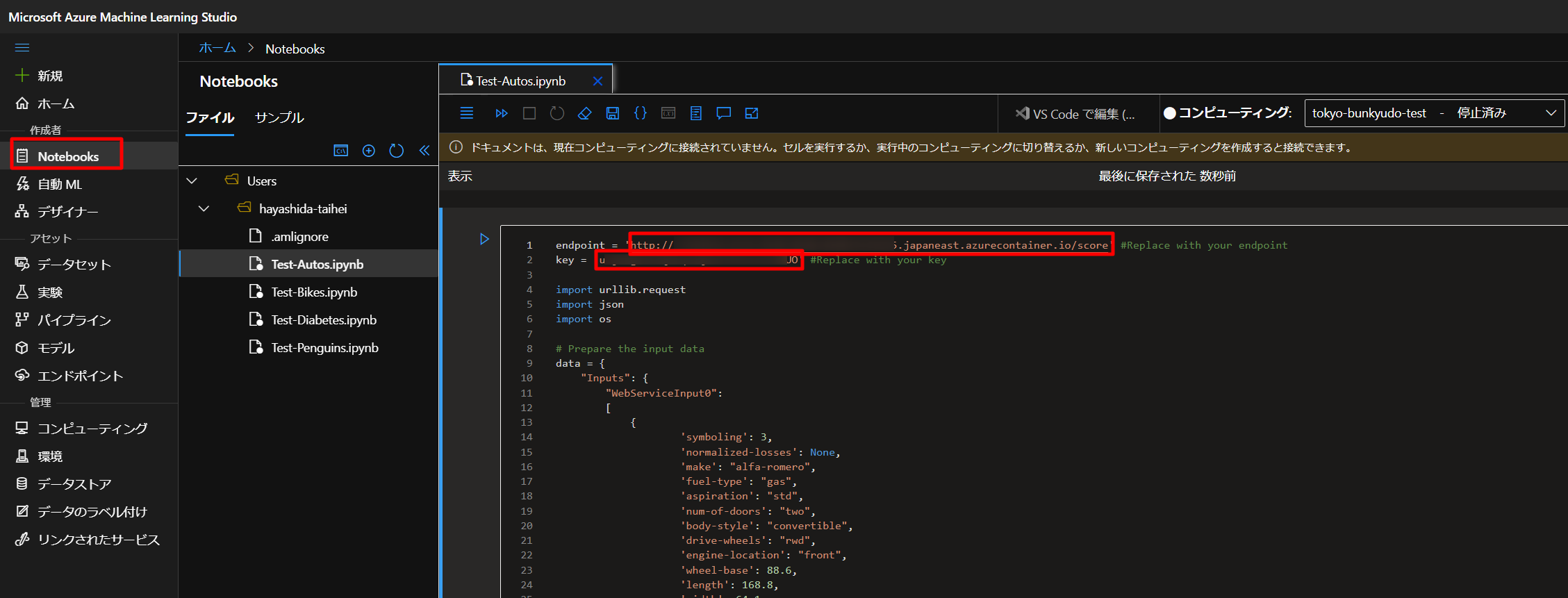
下図のように、Notebooksで新しいファイルを作成し、ファイルの種類はノートブックとします。
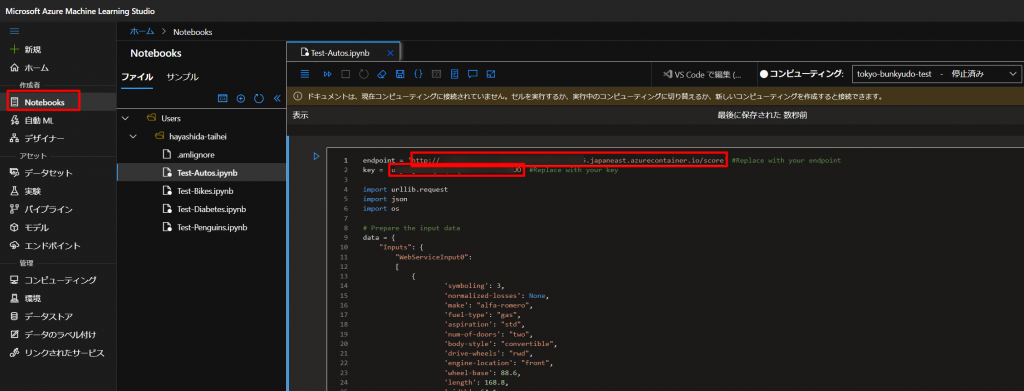
上図のように、以下のプログラムをコピペして、STEP8で生成したエンドポイントと主キーをYOUR_ENDPOINTとYOUR_KEYに入れていきます。
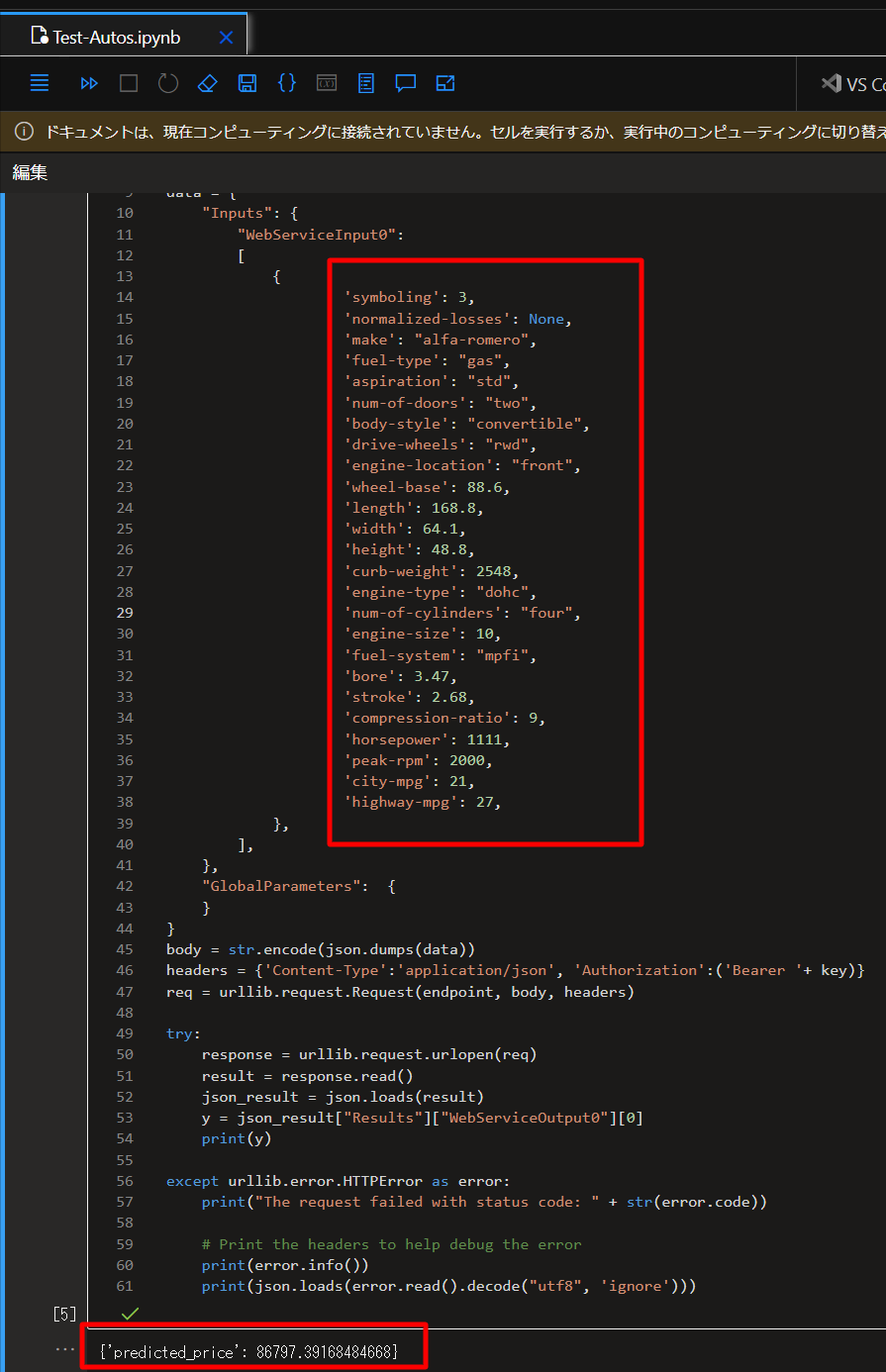
endpoint = 'YOUR_ENDPOINT' #Replace with your endpoint key = 'YOUR_KEY' #Replace with your key import urllib.request import json import os # Prepare the input data data = { "Inputs": { "WebServiceInput0": [ { 'symboling': 3, 'normalized-losses': None, 'make': "alfa-romero", 'fuel-type': "gas", 'aspiration': "std", 'num-of-doors': "two", 'body-style': "convertible", 'drive-wheels': "rwd", 'engine-location': "front", 'wheel-base': 88.6, 'length': 168.8, 'width': 64.1, 'height': 48.8, 'curb-weight': 2548, 'engine-type': "dohc", 'num-of-cylinders': "four", 'engine-size': 130, 'fuel-system': "mpfi", 'bore': 3.47, 'stroke': 2.68, 'compression-ratio': 9, 'horsepower': 111, 'peak-rpm': 5000, 'city-mpg': 21, 'highway-mpg': 27, }, ], }, "GlobalParameters": { } } body = str.encode(json.dumps(data)) headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ key)} req = urllib.request.Request(endpoint, body, headers) try: response = urllib.request.urlopen(req) result = response.read() json_result = json.loads(result) y = json_result["Results"]["WebServiceOutput0"][0] print(y) except urllib.error.HTTPError as error: print("The request failed with status code: " + str(error.code)) # Print the headers to help debug the error print(error.info()) print(json.loads(error.read().decode("utf8", 'ignore')))仮に以下のように設定して、Shift+Enterなどで実行すると、以下のような結果を得られます。
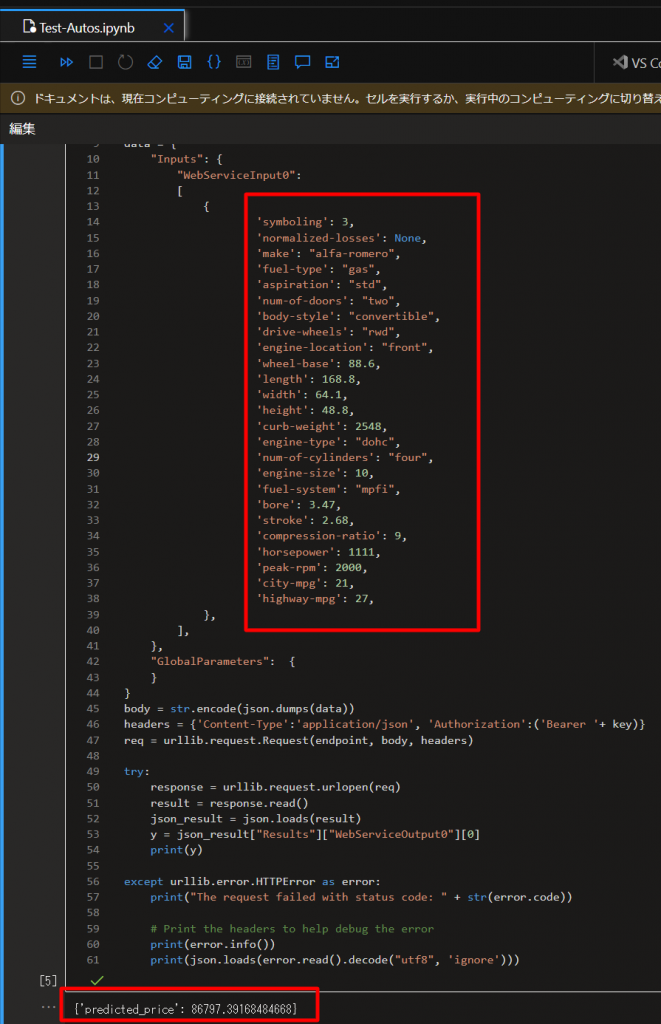

さいごに
いかがだったでしょうか。ステップは多かったと思いますが、そこまで難しくなく機械学習のテストができると思います。
ただ、最終的には、どのような目的でデータを分析して何を予測するのかということが重要になってくると思いますが、まずはどのようなことができるのかを自分で確認していくことで、新たな気付きが得られるかもしれません。