目次
はじめに
今回は、Microsoft Azureについて、以前から気になってはいたものの、AmazonのAWSやGoogleのGCPなどクラウドとしてはわりと先進的っぽいイメージだったので、そちらをテストしてみたりしていましたが、当社では、Microsoft365も使っていますし、200$くらいのクレジットを無料で試せるということもあり、また、ちょっとだけ時間ができたので、使ってみることにしました。
Microsoft Azureには、学習システムがあり、今回は、それをベースに自分にとってとても興味が深い機械学習についてやってみましたので、そちらをシェアしたいと思います。
前提条件と対象者
今回は、Microsoft Azureのアカウント登録や、仮想コンピュータ、サブスクリプション等の初期設定は省略させていただいております。
また、正直なところ、多少の機械学習の知識がある人を対象としております。(私自身がほぼ素人なので、ここに関してはあまり問題ないと思いますが。)
最終系
お忙しい人は、こちらの動画をご覧ください。
説明
正直、今回は、Microsoft AzureのMLについての学習を見ながら動画を撮影しておりますので、そのラーニングシステムを見ていただいたらいいかとは思いますが、流れや、重要そうなポイントだけちょっとだけ解説したいと思います。

- STEP
データセットの設定
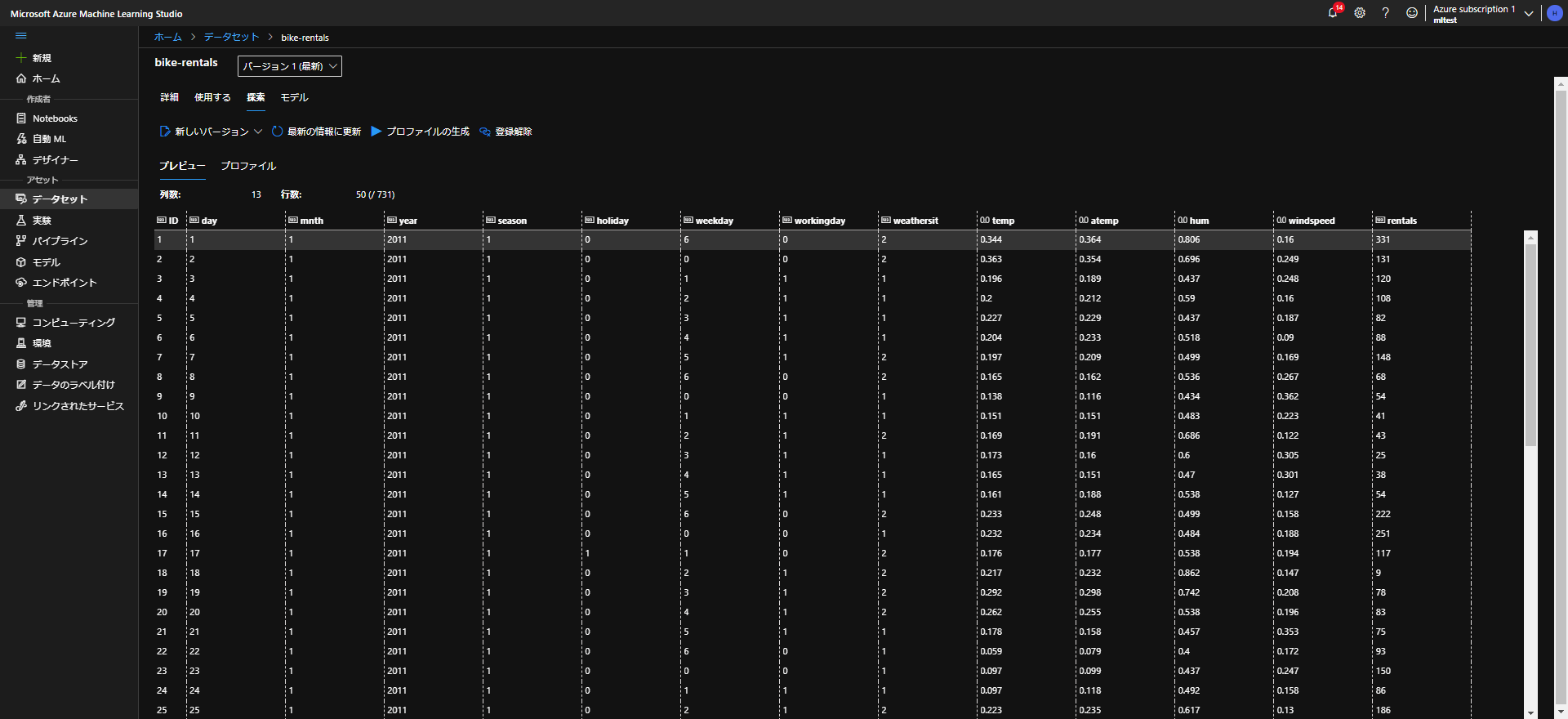
当然ですが、何かの予測をする際には、何を予測するのか、とどういうデータからその目的とするデータを予測するのかという情報が必要になります。
そこで、今回は、上記URLでの学習で使用しております、自転車レンタルの数を予測するということをやっていきます。
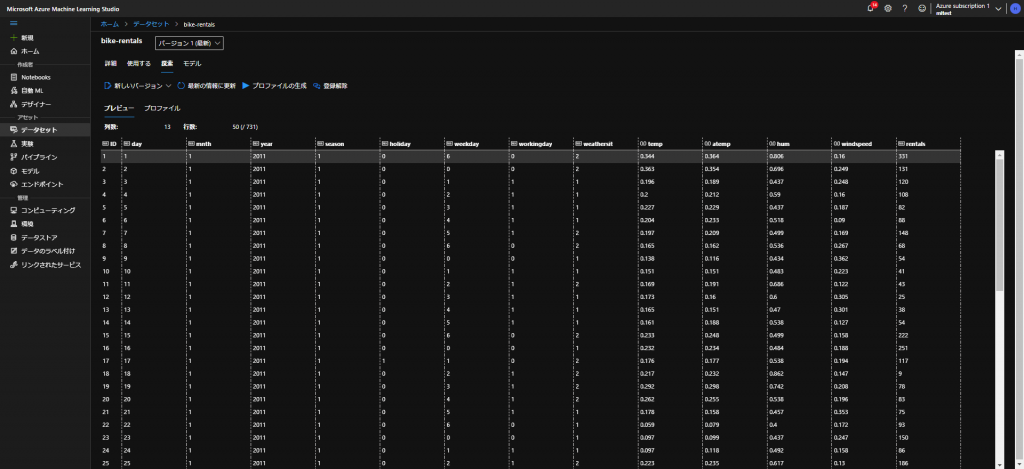
かなり見づらいかと思いますが、一番右にある「rentals」というレンタル数を予測するということをやっていきます。
- STEP
モデルの構築
とても親切なことに、自動で学習するシステムをMicrosoft側が用意してくれておりますので、今回は、この学習に沿って使っていきます。
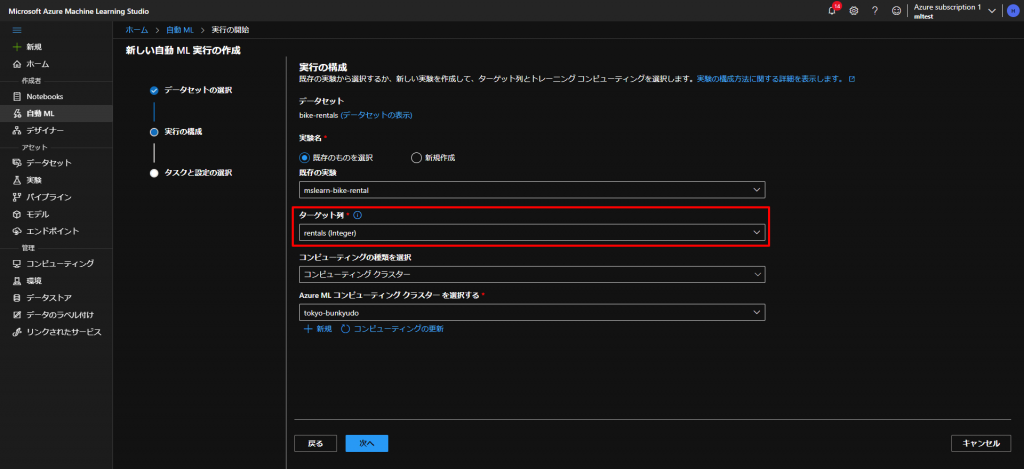
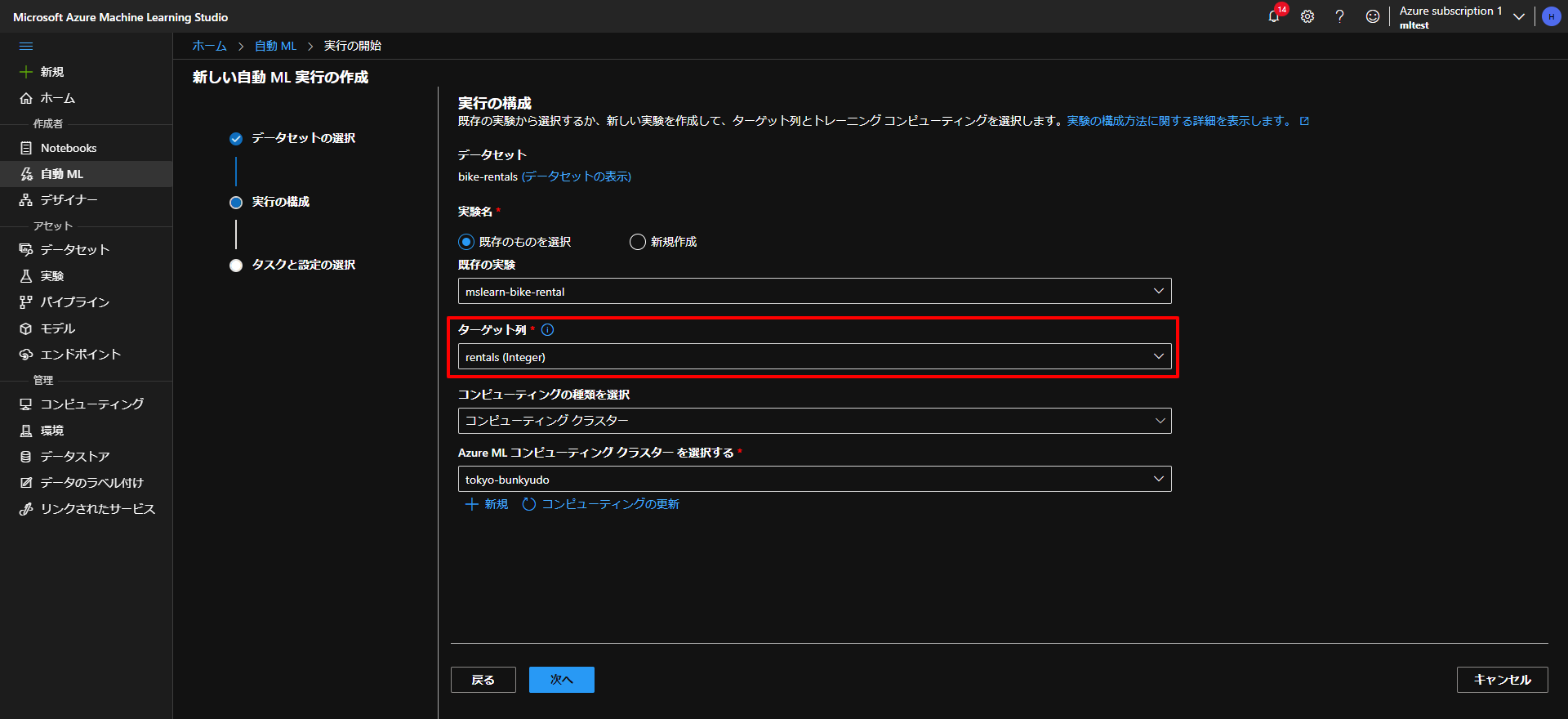
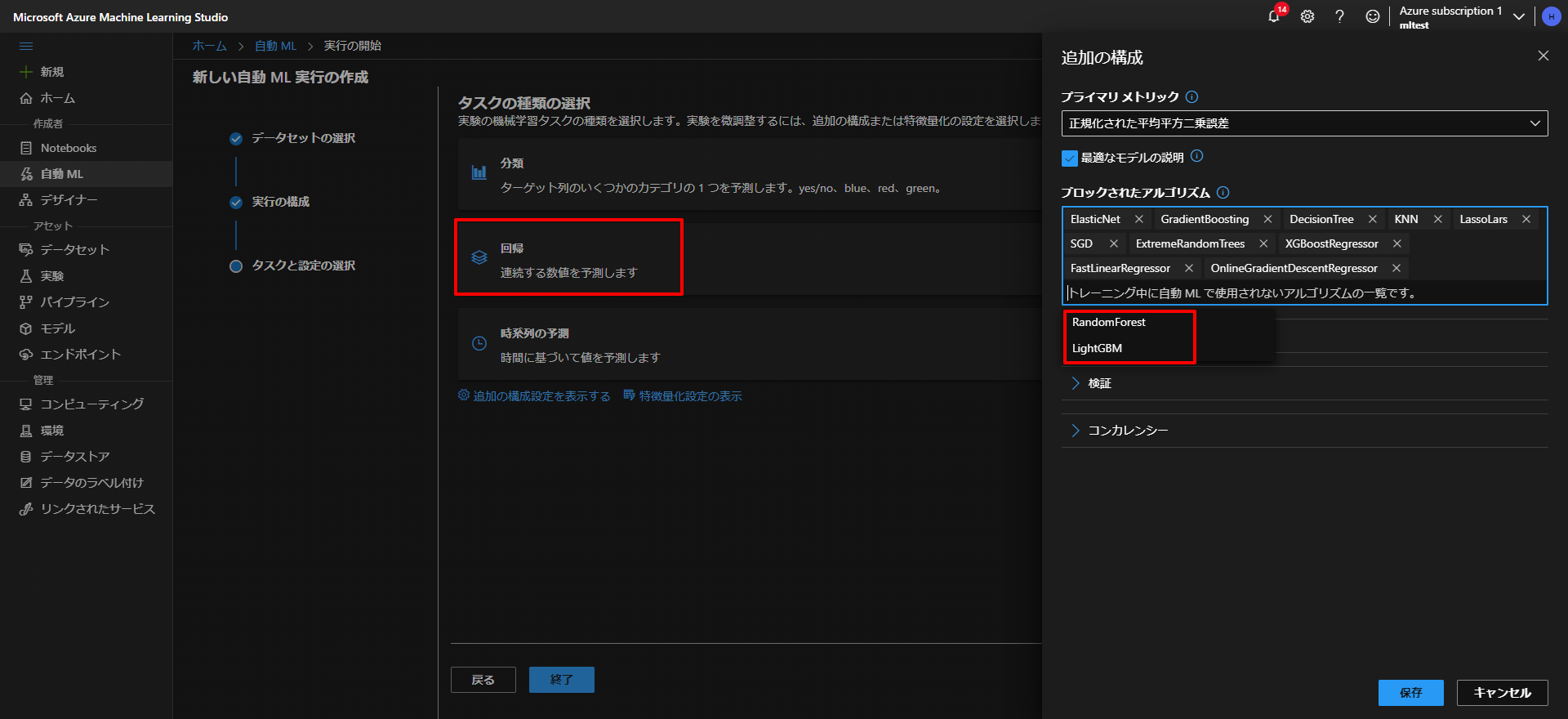
上記から次へを押すと、タスクの設定の選択になるのですが、ここでちょっとしたテクニックになります。
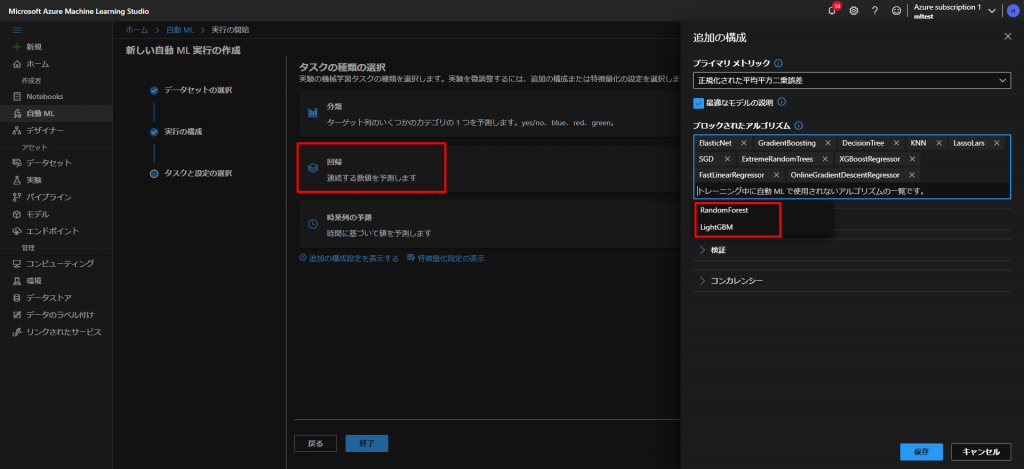
まず、分類、回帰、時系列の予測とありますが、今回は、ある数値(レンタル数がどのくらいになるか)を予測したいので、その場合は「回帰」を選択します。
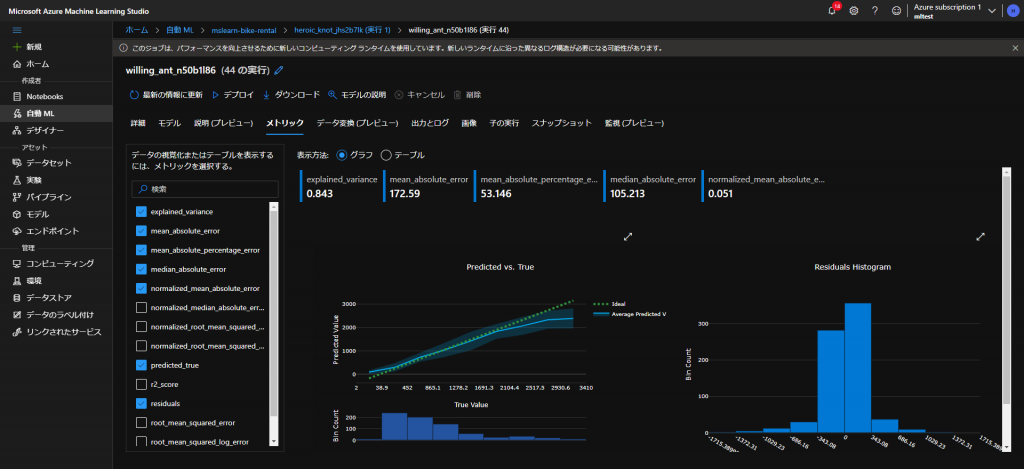
学習が終了すると、下図のように学習が終わった状態を視覚的に確認することができます。
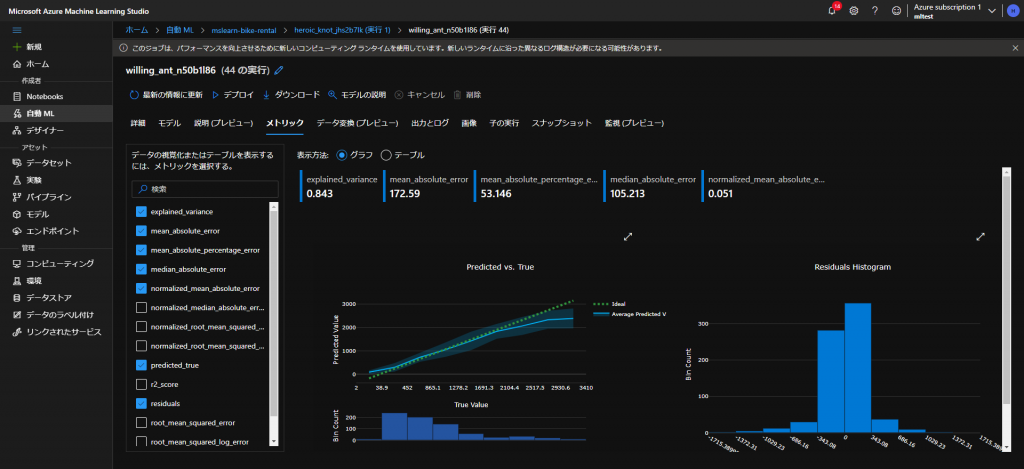
- STEP
モデルのデプロイ
ここでデプロイという謎の単語が出てきます。
せっかく予測するモデルを作ったのだから、これを使える状態にしたいということで、その状態を構築するといった意味でしょうか、要は、新しい情報が入って、何か結果を返してくれるそんな状態にする作業をします。
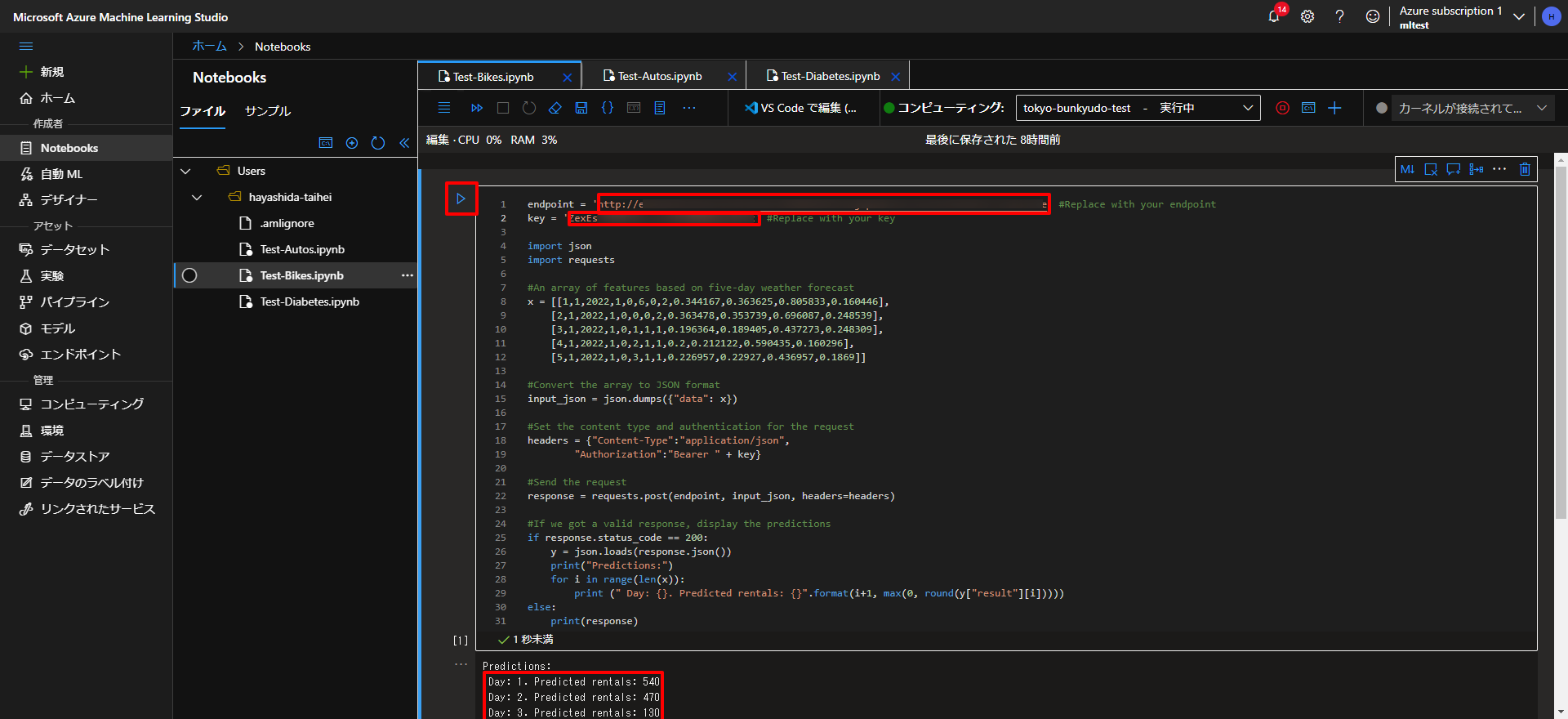
ここで、残念ながら、Pythonというプログラムが登場して、もはやわけわからないですが、以下のコードを「Notebooks」というところで、新規で作成していきます。
endpoint = 'YOUR_ENDPOINT' #Replace with your endpoint key = 'YOUR_KEY' #Replace with your key import json import requests #An array of features based on five-day weather forecast x = [[1,1,2022,1,0,6,0,2,0.344167,0.363625,0.805833,0.160446], [2,1,2022,1,0,0,0,2,0.363478,0.353739,0.696087,0.248539], [3,1,2022,1,0,1,1,1,0.196364,0.189405,0.437273,0.248309], [4,1,2022,1,0,2,1,1,0.2,0.212122,0.590435,0.160296], [5,1,2022,1,0,3,1,1,0.226957,0.22927,0.436957,0.1869]] #Convert the array to JSON format input_json = json.dumps({"data": x}) #Set the content type and authentication for the request headers = {"Content-Type":"application/json", "Authorization":"Bearer " + key} #Send the request response = requests.post(endpoint, input_json, headers=headers) #If we got a valid response, display the predictions if response.status_code == 200: y = json.loads(response.json()) print("Predictions:") for i in range(len(x)): print (" Day: {}. Predicted rentals: {}".format(i+1, max(0, round(y["result"][i])))) else: print(response)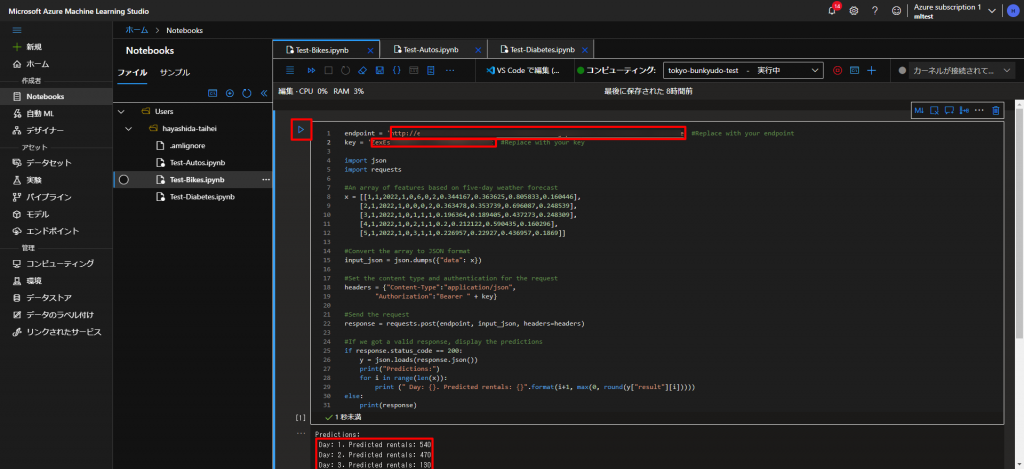
上のコードの、「endpoint」と「key」をSTEP2で生成されたものを入力して、上図の「▷」ボタン(もしくはShift+enter)を押して、しばらくすると、上図の下のように、結果が返ってきます。
結果で言いますと、例えば、2022年1月1日が、上記で設定したような、気温、湿度、風の強さだったとしたら、どのくらいのレンタル数が予想されるかといったことが分かるということです。
当然、季節や時期、天候状態等もありますが、その年、その時の豊かさや流行、健康志向といったものもあると思いますので、一概に自転車レンタルについてその時にどのくらいかなどは分からないと思いますが、一つの目安にはなるかと思います。
どのくらいの従業員が必要になりそうかなどの予算策定などには使えるかもしれません。

さいごに
いかがだったでしょうか。感想としては、ほとんどノーコードで実装できるので、プログラミング初心者でもわりと簡単に実装できるのではないでしょうか。
今回は、自動MLで回帰というものを使っていきましたが、次回は、自分で作ったモデルで実装したものをシェアしたいと思います。
30日しか無料でできる期間がないので、できる限りテストして皆さんにシェアできればと考えております。