テキストエディタなどでアルファベットや日本語の文字などを入力した時など、文字はコンピュータの内部で数値で管理されています。
文字と文字コードの対応表が共通であれば何の問題も無いのですが、世の中には文字と文字コードの対応表が複数存在しています。例えばある対応表だと文字「高」と言う文字は102番なのに他の対応表では「高」と言う文字は10546番などといった感じです。
どの文字がどの文字コードになるかの集合を文字集合と言います。または文字集合の事を単に文字コードと呼ぶことも多いです。
〇文字コードの種類
漢字などがない米国などではアルファベットといくつかの記号だけで文字を表現することができますので比較的少ない文字集合で済みます。このアルファベットと記号だけが定義された代表的な文字コードが ASCII です。
これに対して日本語などではひらがなやカタカナに加えて漢字など数多くの文字が存在しますので、日本で使う文字集合は含まれている文字が多くなっています。そして文字集合の中の文字とコードをどのように対応させるのかによって Shift_JIS、EUC-JP、ISO-2022-JP などの文字コードが存在します。(正確には対象となる文字の集合は微妙に違います)。
Shift_JISは主にWindowsで使われている文字コードであり、EUC-JPは主にUNIX系で使われている文字コードです。ISO-2022-JPはJISコードと呼ばれることもあり主に電子メールで使われる文字コードです。日本語だけでも多くの文字コードが使われているため、同じ文字であっても色々なコードが存在します。
■Unicode
漢字などを使うのは日本だけではありませんし、他の国ではアルファベットでも日本語でもない文字を使っている国も多数あります。国毎に様々な文字集合と文字コードが使われていますが全世界で使われている文字を一つの文字集合として定義しようとしたのが Unicode です。
そしてUnicodeとして定義された文字集合の中の文字をどのようにコードへ対応させるのかによって UTF-8 や UTF-16 などの文字コードがいくつか存在します。
UTF-8 は現在インターネットで標準の文字コードになりつつあり、様々なところで使われるようになってきています。
〇文字コードと文字化け
同じ文字であっても使っている文字コードによって対応する数値が異なるため、一度保存したデータを別の文字コードを使って書かれたものとしてて読み込もうとすると文字化けが発生します。多くのアプリケーションでは保存されたデータから使われている文字コードを判別してくれますが、自動判別に失敗する場合もあります。
またWebページではWebページ内に使用した文字コードを明記することができますが、実際に保存した時の文字コードとWebページ内に記載した文字コードが異なっていた場合にも文字化けが発生します。
文字化けが起こる原因は一つではありませんが、文字コードが間違っていないかを調べてみるといいでしょう。
〇文字コードはどんな時に使われるのか
Windowsに標準で付属しているメモ帳にて「名前を付けて保存」を行う時、画面一番下で文字コードを選択することができます。
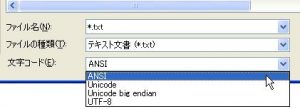
メモ帳では「ANSI」「Unicode」「Unicode big endian」「UTF-8」から文字コードを選択できます。デフォルトでは「ANSI」となっており「ANSI」を選択した場合に日本のWindowsXPではShift_JIS(CP932)を使って保存されます(なぜANSIとなっているかは不明です)。
※なおメモ帳では「UTF-8」も選択できますが、必ずBOM付きとなるので注意して下さい。UTF-8におけるBOMというのは文字コードの判定の時にUnicodeかどうかを識別できるようにファイルの先頭に挿入される短いデータのことです。
またブラウザでホームページを閲覧する場合にもホームページがどの文字コードで記述されたのか判別しなければなりません。
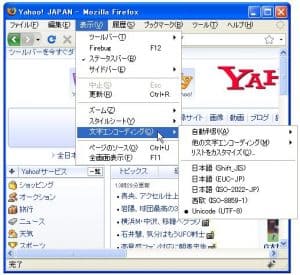
正しく作成されたホームページであれば、ブラウザの設定を自動判別にしておくことでほぼ問題無く表示してくれます。もし文字化けして表示されるホームページがあった場合には文字コードを自分で指定することで正常に見れる場合があります。