
AI分野に興味を持って、AI実装検定A級、G検定と取得はしたものの、AIのできるツールのレビューくらいで、まだ実用的に分析していなかったので、E資格取得を見据えた自らのアウトプットとともに、内容をシェアできればと思います。

AIの初学者用にいくつかのデータセットが親切にも無料で公開されていたりするので、それを同じようにやっていくのも勉強にはなるのですが、せっかくなので、「Kaggle」というAIのコンペティションをやっているサイトから、面白そうなデータセットがあったので、今回は、「技術系企業のメンタルヘルス」に関するデータセットを用いて分析していきます。
Kaggleは企業や研究者がデータを投稿し、世界中の統計家やデータ分析家がその最適モデルを競い合う、予測モデリング及び分析手法関連プラットフォーム及びその運営会社である。
https://ja.wikipedia.org/wiki/Kaggle
データのインポート、データの確認からはじめて、ゴリゴリにプログラムを書いて、分析までしていくので、数回にわたって解説していきたいと思います。
どのデータを分析するにもたいてい同じステップだと思いますが、今回分析していくステップを先に説明します。
- STEP
データの読み込み
必要なライブラリを用意して、データを読み込んでいきます。
- STEP
データの確認
データがどういう状態かを確認します。
- STEP
データの前処理
データを分析するために必要な加工を施していきます。
- STEP
データの関係性の確認
グラフなどの機能を使って、データ間の関係性を確認していきます。
- STEP
スケーリング
データ間の割合の調整をしていきます。
具体的には、各データを公平に判断するように設定します。 - STEP
アルゴリズムも選択&学習
実際にAI学習(機械学習)を行うアルゴリズムを選択して、学習していきます。
- STEP
評価
実際に学習したデータの精度などで評価します。
さて、それでは、さっそく実装していきます。
今回も、Google Colaboratoryを使っていきたいと思います。

その前に、データをダウンロードしておきます。
Kaggleからデータをダウンロードしていきます。
今回は「Mental Health in Tech Survey」というテーマのダウンロードしていきます。
※詳細はログイン操作等ありますので、割愛いたします
それでは、必要なライブラリをインポートしていきます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
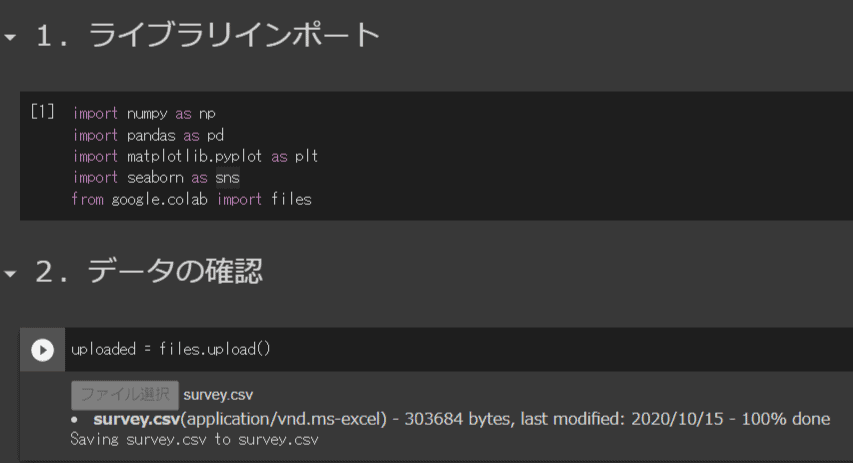
from google.colab import files次に、データをセットします。
uploaded = files.upload()上記を実行するとファイルを選択できるので、ダウンロードしたCSVを選択すると、下図のようになり、データをGoogle Colaboratory上にアップロードできます。
次に、データを確認していきます。
train_df = pd.read_csv("survey.csv")
print(train_df.shape)
print(train_df.describe())上記を入力すると、下図のような統計データが出力されます。
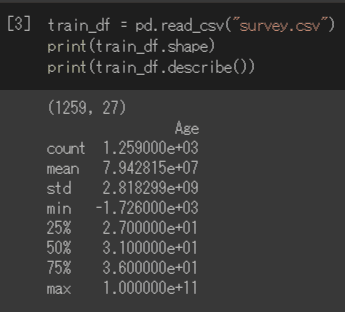
(1259, 27)となっていて、行が1259行、列が27列あり、こちらが意味するところは、1259レコードのデータがあって、分析対象の項目が27個あるということになります。
その下のデータは以下の表の意味となっています。
| count | レコード数 |
| mean | 平均 |
| std | 標準偏差 |
| min | 最小値 |
| 25% | 25%パーセンタイル値 |
| 50% | 50%パーセンタイル値 |
| 75% | 75%パーセンタイル値 |
| max | 最大値 |
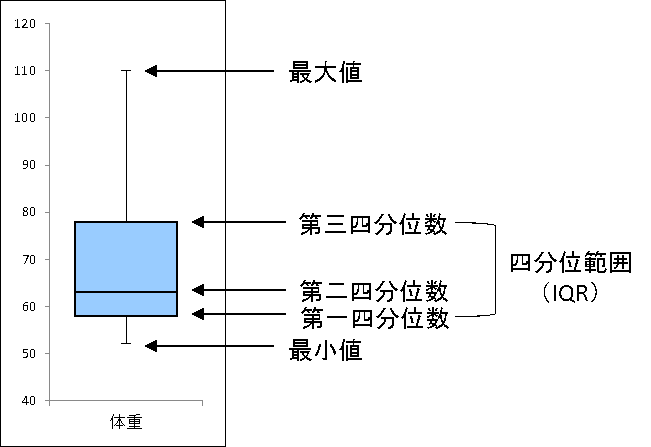
パーセンタイルという言葉は聞きなれないと思いますが、統計データで使われる用語となります。
詳しくは、以下を参照ください。
続いて、実際のデータを見ていきましょう。
display(train_df.head())こちらを実行すると、下図のようにデータの最初の5行が表示されます。
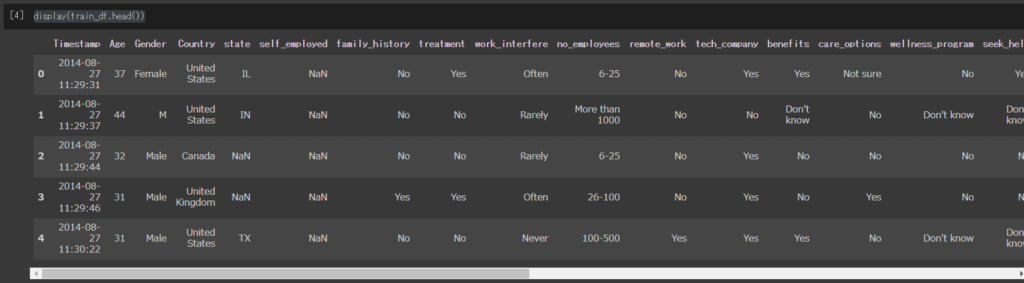
実際に、どんな内容の項目があるのかチェックします。
print(train_df.info())こちらを入力すると、下図のように、どういう項目についてのデータかがわかります。
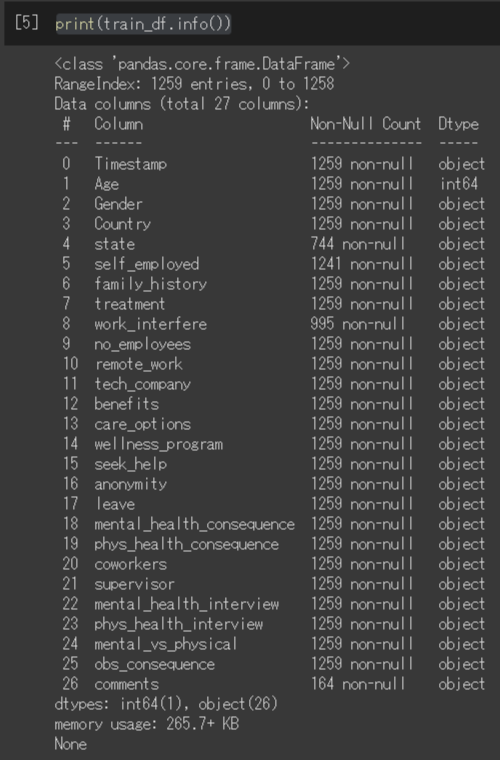
英語なので、どういう内容か日本語に直していきます。
| No | 変数名 | 型 | 項目 |
|---|---|---|---|
| 0 | Timestamp | Numeric | 調査書送付日時 |
| 1 | Age | Numeric | 年齢 |
| 2 | Gender | String | 性別 |
| 3 | Country | String | 所属国 |
| 4 | state | String | 州 |
| 5 | self_employed | String | 自営業 |
| 6 | family_history | String | 家族歴 (家系に精神病にかかった人 がいるか) |
| 7 | treatment | String | 治療歴 (精神病の治療をした ことがあるか) |
| 8 | work_interfere | String | 仕事への干渉 (仕事の妨げになるような 精神状態の時があるか) |
| 9 | no_employees | String | 従業員数 |
| 10 | remote_work | String | リモートワーク (50%は会社外で仕事するか) |
| 11 | tech_company | String | 技術系企業 (技術系企業かどうか) |
| 12 | benefits | String | 福利厚生 (メンタルヘルスの福利厚生 があるかどうか) |
| 13 | care_options | String | 精神衛生オプション (メンタルヘルスに関する 福利厚生オプションを 知っているか) |
| 14 | wellness_program | String | 雇用主に相談 (雇用主とメンタルヘルス に関して相談したことが あるか) |
| 15 | seek_help | String | 雇用主の援助 (雇用主からメンタルヘルス に関する情報提供等が あったか) |
| 16 | anonymity | String | 匿名性の担保 (メンタルヘルスについて 匿名性が保たれているか) |
| 17 | leave | String | 療養の取得環境 (メンタルヘルスに対する 療養はとりやすい環境か) |
| 18 | mental_health_consequence | String | 雇用主とのメンタルヘルス相談で不利 (雇用主にメンタルヘルスで 相談することで不利な結果 になると考えるか) |
| 19 | phys_health_consequence | String | 雇用主との健康相談で不利 (雇用主に健康について 相談することで不利な結果 になると考えるか) |
| 20 | coworkers | String | 同僚に相談 |
| 21 | supervisor | String | 上司に相談 (メンタルヘルスについて 上司に相談したいか) |
| 22 | mental_health_interview | String | 入社面接時のメンタルヘルス (メンタルヘルスについて 入社面接時に質問したいか) |
| 23 | phys_health_interview | String | 入社面接時の健康 (健康面について 入社面接時に質問したいか) |
| 24 | mental_vs_physical | String | メンタルヘルスの重視 (雇用主がメンタルヘルスと 健康面について同じくらい 重視している感じているか) |
| 25 | obs_consequence | String | 同僚のメンタルヘルス (同僚のメンタルヘルスについて 深刻な情報を聞いたことがあるか) |
| 26 | comments | String | 備考 |
上記の表のようにタイトルを日本語に変換していきます。
colums_t = ["調査書送付日時","年齢","性別","所属国","州","自営業","家族歴","治療歴","仕事への干渉","従業員数","リモートワーク","技術系企業","福利厚生","精神衛生オプション","雇用主に相談","雇用主の援助","匿名性の担保","療養の取得環境","雇用主とのメンタルヘルス相談で不利","雇用主との健康相談で不利","同僚に相談","上司に相談","入社面接時のメンタルヘルス","入社面接時の健康","メンタルヘルスの重視","同僚のメンタルヘルス","備考"]
train_df.columns = colums_t
display(train_df.head())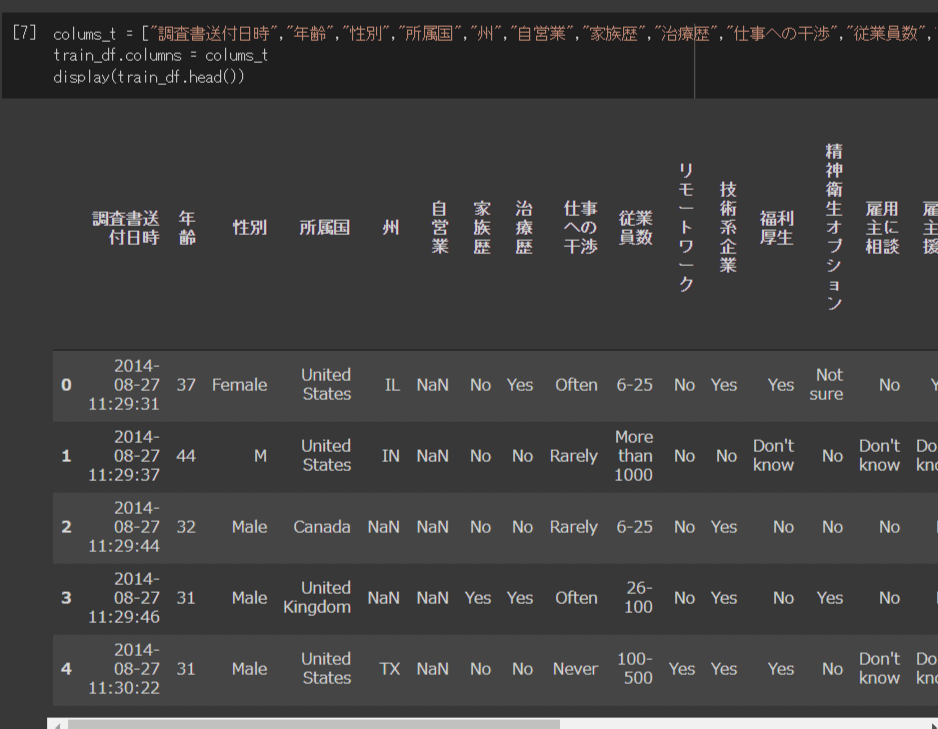
最後に、欠損値を確認して、次回へ続けます。
print(train_df.isnull().sum())上記を入力すると、下記のように、欠損値(データがない)が項目ごとにどれくらいあるかを確認できます。
